خوارزمية أصل التدرج
أصل التدرج هو خوارزمية تحسين تكرارية من الدرجة الأولى للعثور على الحد الأدنى المحلي لدالة قابلة للاشتقاق. للعثور على الحد الأدنى المحلي للدالة باستخدام منحدر التدرج ، نتخذ خطوات تتناسب مع سلبية التدرج (أو التدرج التقريبي) للدالة عند النقطة الحالية. ولكن إذا اتخذنا بدلاً من ذلك خطوات تتناسب مع إيجابية التدرج ، فإننا نقترب من الحد الأقصى المحلي لهذه الدالة؛ يُعرف الإجراء بعد ذلك بصعود متدرج . تم اقتراح خوارزمية أصل التدرج من قبل العالم الرياضي أوغستين لوي كوشي في عام 1847.[1]
وصف
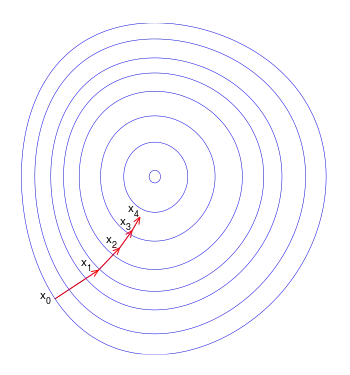
يعتمد أصل التدرج على الملاحظة أنه إذا كانت الدالة متعددة المتغيرات معرفة و قابلة للاشتقاق في جوار النقطة ، فإن ينخفض بسرعة أكبرإذا ذهبنا من في اتجاه التدرج السلبي لـ في .




و يتبع ذلك أنه إذا كان

فإنه لكل صغيرة بما يكفي ، . وبعبارة أخرى ، الحد يطرح من لأننا نريد التحرك ضد التدرج نحو الحد الأدنى المحلي. مع أخذ هذه الملاحظة في الاعتبار ، يبدأ المرء باختيار كنقطة بداية (يمكن اختيارها عشوائيا)،و يعتبر بعد ذلك التسلسل , بحيث:






لدينا تسلسل رتيب

لذا نأمل أن يكون التسلسل يتقارب نحو الحد الأدنى المحلي المطلوب. لاحظ أن قيمة حجم الخطوة يسمح بالتغيير في كل تكرار. مع بعض الافتراضات على الدالة (فمثلا، محدبة و ليبشيتزية ) وخيارات معينة من (على سبيل المثال ، يتم اختياره إما عن طريق البحث الخطي الذي يلبي شروط وولفه، أو طريقة بارزيلاي - بوروين [2][3] الموضحة على النحو التالي):




يمكن ضمان التقارب إلى الحد الأدنى المحلي.
عندما تكون الدالة محدبة ، كل الحدود الدنيا المحلية هي أيضًا حد أدنى عام، لذلك في هذه الحالة يمكن أن يتقارب أصل التدرج إلى الحل العام.
هذه العملية موضحة في الصورة المجاورة. هنا من المفترض أن يتم تعريفها على المستوى ، وأن الرسم البياني له شكل وعاء . المنحنيات الزرقاء هي الخطوط المنسوبية ، أي المناطق التي تكون فيها قيمة ثابتة. يظهر سهم أحمر ينشأ عند نقطة اتجاه التدرج السلبي في تلك النقطة. لاحظ أن التدرج (السلبي) عند نقطة ما هو متعامد مع خط الكفاف الذي يمر عبر تلك النقطة. نرى أن أصل التدرج يقودنا إلى قاع الوعاء ، أي إلى النقطة التي تكون فيها قيمة الدالة هي الحد الأدنى.
أمثلة
يعاني أصل التدرج من مشاكل في الدوال "المرضية" مثل دالة روزين بروك الموضحة هنا.

تحتوي دالة روزين بروك على واد منحني ضيق يحتوي على الحد الأدنى. الجزء السفلي من الوادي مسطح للغاية. بسبب الوادي المسطح المنحني يكون التحسين متعرجًا ببطء مع أحجام خطوات صغيرة نحو الحد الأدنى.
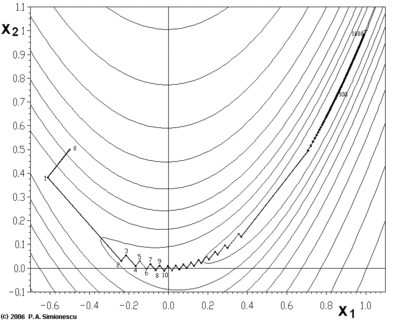
يمكننا رؤية مثال آخر على الطبيعة المتعرجة لهذه الطريقة: فلنطبق خوارزمية أصل التدرج على الدالة التالية:

.png.webp)
.png.webp)
استعمال أصل التدرج في خوارزميات التعلم الآلي
يعتبر أصل التدرج هو أساس خوارزميات التحسين المستخدمة في ميدان التعلم الآلي
حيث تتكون شبكات التعلم الآلي من عدد من العصبونات الاصطناعية، لكل منها وزن و انحياز
فشبكة التعلم الآلي تشكل في الحقيقة دالة متعددة المتغيرات، متغيراتها هي الأوزان و الانحيازات التي تخضع للتدريب
يتلخص تدريب الشبكات العصبية في الخطوات التالية:
1) حساب دالة "الخسارة" : و هي الدالة الناتجة عن حساب الفرق بين قيم مخارج الشبكة العصبية عندما تطبق على مجموعة التدريب، و النتائج الحقيقية المنتظرة من مجموعة التدريب
2) حساب المشتقات الجزئية لدالة الخسارة، بالنسبة لمجموعة الأوزان و الانحيازات
3) تطبيق الانتشار الخلفي عبر خوارزمية أصل التدرج، و ذلك عن طريق طرح المشتقات الجزئية لدالة الخسارة من الأوزان و الانحيازات (بعد ضربها بمعامل التعلم)، و إعادة الخطوات 1) و 2) و 3) في طريق التدرج نحو الحد الأدنى لدالة الخسارة
[4]
تعليقات
يعمل أصل التدرج في فضاءَات متعددة الأبعاد و حتى في الأبعاد اللانهائية.
في حالة الأبعاد اللانهائية، تكون مساحة البحث عادةً عبارة عن فضاء دالي ، و نحسب مشتقة فريشيه الخاصة بالدالة التي سيتم تصغيرها لتحديد اتجاه الهبوط.[5]
يمكن أن يستغرق أصل التدرج العديد من التكرارات لحساب الحد الأدنى المحلي بالدقة المطلوبة إذا كان انحناء الدالة مختلفا اختلافا كبيرا حسب الاتجاهات. لمثل هذه الدوال، فإن التهيئة المسبقة ، التي تغير هندسة المساحة لتشكيل مجموعات مستوى الدالة مثل الدوائر المتحدة المركز ، تعالج التقارب البطيء. ومع ذلك ، يمكن أن يكون إنشاء وتطبيق الشروط المسبقة مكلفًا من الناحية الحسابية.
يمكن دمج أصل التدرج مع بحث خطي ، للعثور على حجم الخطوة الأمثل محليًا في كل تكرار. يمكن أن يستغرق إجراء البحث الخطي وقتًا طويلاً.
على العكس من ذلك ، باستخدام ثابتة صغيرة يمكن أن يسفر عن تقارب ضعيف.
يمكن أن تكون الطرق المستندة إلى طريقة نيوتن وانقلاب الهسيان باستخدام تقنيات التدرج المترافق بدائل أفضل.[6][7] بشكل عام ، تتقارب هذه الأساليب في عدد أقل من التكرارات ، ولكن تكلفة كل تكرار أعلى. ومن الأمثلة على ذلك طريقة BFGS التي تتكون من حساب مصفوفة في كل خطوة يتم من خلالها ضرب متجهة التدرج للذهاب إلى اتجاه "أفضل" ، مقترنًا بخوارزمية بحث خطي أكثر تعقيدًا ، للعثور على القيمة "الأفضل" لـ

بالنسبة للمسائل الكبيرة للغاية ، حيث تهيمن مشاكل ذاكرة الكمبيوتر ، يجب استخدام طريقة محدودة الذاكرة مثل L-BFGS بدلاً من BFGS أو أصل التدرج.
يمكن النظر إلى أصل التدرج على أنه تطبيق طريقة أويلر لحل المعادلات التفاضلية العادية لتدفق متدرج .

أمثلة حسابية
تطبق أمثلة التعليمات البرمجية التالية خوارزمية أصل التدرج للعثور على الحد الأدنى للدالة مع مشتقة:


حل ل وتقييم المشتق الثاني عند الحلول يبين أن الدالة لها نقطة هضبة عند 0 والحد الأدنى العام عند


بيثون
فيما يلي تطبيق بلغة برمجة Python :
next_x = 6 # We start the search at x=6
gamma = 0.01 # Step size multiplier
precision = 0.00001 # Desired precision of result
max_iters = 10000 # Maximum number of iterations
# Derivative function
def df(x):
return 4 * x ** 3 - 9 * x ** 2
for _ in range(max_iters):
current_x = next_x
next_x = current_x - gamma * df(current_x)
step = next_x - current_x
if abs(step) <= precision:
break
print("Minimum at ", next_x)
# The output for the above will be something like
# "Minimum at 2.2499646074278457"
سكالا
هنا تنفيذ في لغة برمجة سكالا
import math._
val curX = 6
val gamma = 0.01
val precision = 0.00001
val previousStepSize = 1 / precision
def df(x: Double): Double = 4 * pow(x, 3) - 9 * pow(x, 2)
def gradientDescent(precision: Double, previousStepSize: Double, curX: Double): Double = {
if (previousStepSize > precision) {
val newX = curX + -gamma * df(curX)
println(curX)
gradientDescent(precision, abs(newX - curX), newX)
} else curX
}
val ans = gradientDescent(precision, previousStepSize, curX)
println(s"The local minimum occurs at $ans")
جافا
import java.util.function.Function;
import static java.lang.Math.pow;
import static java.lang.Math.abs
double gamma = 0.01;
double precision = 0.00001;
Function<Double,Double> df = x -> 4 * pow(x, 3) - 9 * pow(x, 2);
double gradientDescent(Function<Double,Double> f) {
double curX = 6.0;
double previousStepSize = 1.0;
while (previousStepSize > precision) {
double prevX = curX;
curX -= gamma * f.apply(prevX);
previousStepSize = abs(curX - prevX);
}
return curX;
}
double res = gradientDescent(df);
System.out.println(String.format("The local minimum occurs at %f", res));
مراجع
- Lemaréchal, C. (2012). "Cauchy and the Gradient Method" (PDF). Doc Math Extra: 251–254. مؤرشف من الأصل (PDF) في 29 ديسمبر 2018. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Barzilai, Jonathan; Borwein, Jonathan M. (1988). "Two-Point Step Size Gradient Methods". IMA Journal of Numerical Analysis. 8 (1): 141–148. doi:10.1093/imanum/8.1.141. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Fletcher, R. (2005). "On the Barzilai–Borwein Method". In Qi; Teo, K.; Yang, X. (المحررون). Optimization and Control with Applications. 96. Boston: Springer. صفحات 235–256. ISBN 0-387-24254-6. الوسيط
|CitationClass=تم تجاهله (مساعدة) - "Gradient Descent" (باللغة الإنجليزية). مؤرشف من الأصل في 01 مايو 2020. اطلع عليه بتاريخ 01 مايو 2020. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Akilov, G. P.; Kantorovich, L. V. (1982). Functional Analysis (الطبعة 2nd). Pergamon Press. ISBN 0-08-023036-9. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Press, W. H.; Teukolsky, S. A.; Vetterling, W. T.; Flannery, B. P. (1992). Numerical Recipes in C: The Art of Scientific Computing (الطبعة 2nd). New York: Cambridge University Press. ISBN 0-521-43108-5. مؤرشف من الأصل في 30 أبريل 2020. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Strutz, T. (2016). Data Fitting and Uncertainty: A Practical Introduction to Weighted Least Squares and Beyond (الطبعة 2nd). Springer Vieweg. ISBN 978-3-658-11455-8. الوسيط
|CitationClass=تم تجاهله (مساعدة)
 صور وملفات صوتية من كومنز
صور وملفات صوتية من كومنز
 بوابة تحليل رياضي
بوابة تحليل رياضي بوابة رياضيات
بوابة رياضيات