ترتيب سريع
الترتيب السريع (بالإنجليزية: Quicksort) هي خوارزمية لترتيب المصفوفات (تصاعديّا أو تنازليّا) من ابتكار الإنجليزي توني هور في 1961.[1][2][3][4]
| ترتيب سريع | |
|---|---|
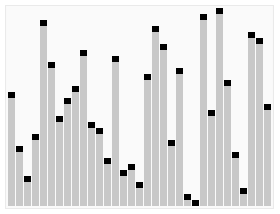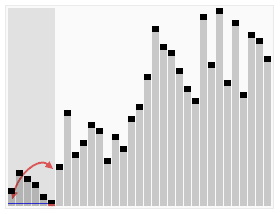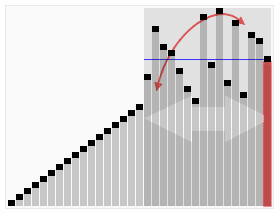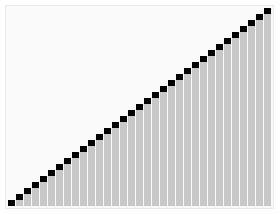 تصور متحرك لخوارزمية الفرز السريع. الخطوط الأفقية هي قيم محورية. | |
| بيانات عامّة | |
| الصنف | خوارزمية الفرز |
| الأداء في أسوء حالة | O(n2) |
| الأداء في الحالة المُثلى | O(n log n) (قسم بسيط) or O(n) (ثلاثي التقسيم ومفاتيح متساوية) |
| الأداء الوسطي | O(n log n) |
| أسوء حالة في تعقيد الفضاء | O(n) مساعد (بسيط) O(log n) مساعد (هوار 1962) |
ترتيب سريع هي خوارزمية فرز فعالة . تم تطويره بواسطة عالم الكمبيوتر البريطاني توني هور في عام 1959 [5] ونشر في عام 1961، [6] ولا يزال خوارزمية الفرز شائعة الاستخدام. عندما يتم تنفيذه بشكل جيد، يمكن أن يكون أسرع إلى حد ما من دمج الفرز وحوالي مرتين أو ثلاث مرات أسرع من فرز الكومة . [7]
الترتيبال سريع هو خوارزمية فرق تسد . إنه يعمل عن طريق تحديد عنصر "محوري" من المصفوفة وتقسيم العناصر الأخرى إلى مصفوفتين فرعيتين، وفقًا لما إذا كانت أقل من المحور أو أكبر منه. لهذا السبب، يطلق عليه أحيانًا فرز تبادل الأقسام . [8] ثم يتم فرز المصفوفات الفرعية بشكل متكرر . يمكن القيام بذلك في نفس المكان، مما يتطلب مساحات إضافية صغيرة من الذاكرة لإجراء الفرز.
كما أن الترتيبال سريع هو نوع للمقارنة، مما يعني أنه يمكنه فرز العناصر من أي نوع يتم تحديد علاقة "أقل من" (رسميًا، ترتيب إجمالي ). لا تعد عمليات التنفيذ الفعالة لـ ترتيب سريع من النوع المستقر، مما يعني أنه لا يتم الاحتفاظ بالترتيب النسبي لعناصر الفرز المتساوية.
يُظهر التحليل الرياضي للفرز السريع أن الخوارزمية، في المتوسط، تأخذ O ( n سجل ن ) مقارنات لفرز ن العناصر. في أسوأ الحالات، تقوم بإجراء مقارنات O (n 2 )، على الرغم من أن هذا السلوك نادر.
تاريخ
تم تطوير خوارزمية الفرز السريع في عام 1959 من قبل توني هور عندما كان طالبًا زائرًا في جامعة موسكو الحكومية . في ذلك الوقت، كان هور يعمل على مشروع ترجمة آلية للمختبر الفيزيائي الوطني . كجزء من عملية الترجمة، كان بحاجة إلى فرز الكلمات في الجمل الروسية قبل البحث عنها في قاموس روسي إنجليزي، والذي كان بالترتيب الأبجدي على شريط مغناطيسي . [9] بعد أن أدرك أن فكرته الأولى، نوع الإدراج، ستكون بطيئة، توصل إلى فكرة جديدة. لقد كتب جزء القسم في ميركوري أوتوكود ولكنه واجه مشكلة في التعامل مع قائمة المقاطع التي لم يتم فرزها. عند العودة إلى إنجلترا، طُلب منه كتابة رمز لـ الترتيب. ذكر هور لرئيسه أنه يعرف خوارزمية أسرع وراهن رئيسه بستة بنسات على أنه لم يعرفها. وافق رئيسه في النهاية على أنه خسر الرهان. في وقت لاحق، تعلم هور عن لغة ألغول للبرمجة وقدرته على القيام بالعودة التي مكنته من نشر الكود في مجلة علوم الاتصالات وآلات الحوسبة (بالإنجليزية: Communications of the Association for Computing Machinery)، وهي مجلة علوم الكمبيوتر الأولى في ذلك الوقت. [6] [10]
اكتسب ترتيب سريع اعتمادًا واسع النطاق، حيث ظهر، على سبيل المثال، في يونكس باعتباره روتين فرعي افتراضي لفرز المكتبة. ومن ثم، أعار اسمها إلى الروتين الفرعي للمكتبة القياسية C.qsort [11] وفي تنفيذ المرجع لجافا.
تعتبر أطروحة الدكتوراه لروبرت سيدجويك في عام 1975 علامة فارقة في دراسة ترتيب سريع حيث قام بحل العديد من المشكلات المفتوحة المتعلقة بتحليل مخططات الاختيار المحوري المختلفة بما في ذلك العينات والتقسيم التكيفي بواسطة فان إمدن [12] بالإضافة إلى اشتقاق العدد المتوقع المقارنات والمقايضات. [11] قام جون بنتلي ودوغ ماكلروي بدمج تحسينات مختلفة للاستخدام في مكتبات البرمجة، بما في ذلك تقنية للتعامل مع العناصر المتساوية والمخطط المحوري المعروف باسم pseudomedian of تسعة، حيث يتم تقسيم عينة من تسعة عناصر إلى مجموعات من ثلاثة ثم متوسط يتم اختيار ثلاثة وسطاء من ثلاث مجموعات. [11] وصف بنتلي مخطط تقسيم آخر أبسط ومضغوط في كتابه لآلئ البرمجة التي نسبها إلى نيكو لوموتو. كتب بنتلي لاحقًا أنه استخدم نسخة هور لسنوات لكنه لم يفهمها أبدًا، لكن نسخة لوموتو كانت بسيطة بما يكفي لإثبات صحتها. [13] وصفت بنتلي ترتيب سريع بأنها "أجمل رمز كتبته على الإطلاق" في نفس المقال. تم أيضًا تعميم مخطط تقسيم لوموتو من خلال مقدمة الكتاب المدرسي للخوارزميات على الرغم من أنه أدنى من مخطط هور لأنه يقوم O(n2) وقت التشغيل عندما تكون جميع العناصر متساوية. [14]
في عام 2009، اقترح فلاديمير ياروسلافسكي تطبيق ترتيب سريع جديدًا باستخدام محورين بدلاً من واحد. [15] في القوائم البريدية لمكتبة جافا الأساسية، بدأ نقاشًا يدعي فيه أن خوارزميته الجديدة متفوقة على طريقة فرز مكتبة وقت التشغيل، والتي كانت تعتمد في ذلك الوقت على المتغير المستخدم على نطاق واسع والمضبوط بعناية من ترتيب سريع الكلاسيكي بواسطة بنتلي وماكلروي. [16] تم اختيار الترتيب السريع لـ ياروسلافسكي كخوارزمية فرز افتراضية جديدة في مكتبة وقت تشغيل جافا 7 من أوراكل [17] بعد اختبارات أداء تجريبية مكثفة. [18]
عن التفضيلات والخوارزمية
تنبني الخوارزمية على وضع العنصر الأول في المصفوفة (بإتخاذه محورًا), ثم ترتيب ووضع العناصر الأكبر من هذا المحور إلى جهة اليمنى من المصفوفة ووضع العناصر الأصغر في الجهة اليسرى. بهذه الطريقة يعتبر المحور في مكانه النهائي المرتّب. تسمى هذه العملية تجزئة ليتبقى من المصفوفة جزئين لم يتم ترتيبهما. نقوم بعد ذلك بإعادة هذه الطريقة على الجزئين المتبقيين من المصفوفة وهكذا نحدد محورا جديدا ونعيد عملية التجزئة. تتكرر هذه العملية إلى أن نحصل على مجموعة مرتبة.
إذا تم اختيار المحور بطريقة صحيحة، نحصل على الطريقة الأسرع للترتيب في الحالة المتوسطة، مع تعقيد ب. والتي قد تتحول إلى في الحالة الأصعب، وهي حالة جدول عناصره مرتبة أصلا. ولكن هذه الحالة بديهية لأن المجموعة مرتبة أصلا.


في الناحية العملية، بالنسبة للتجزئات مع عدد قليل لا يتجاوز بضع عشرات من العناصر، يتم اللجوء عادة إلى الترتيب بالإدراج الذي يكون أفضل من الترتيب السريع.
و بصفة عامة يعتبر الترتيب السريع الأكثر شيوعا (شعبية) من بين جميع خوارزميات الترتيب.
المشكلة الوحيدة تتمثل في كيفية اختيار المحور.
اختيار أفضل مؤشر
عند استعمال الترتيب السريع لمجموعة مرتبة مسبقا، وبطريقة اعتباطية، يستغرق كما قلنا وقتا كبيرا، وذلك راجع لأن أول عنصر هو الذي يعتبر محورا، الشيء الذي يؤدي إلى عدم تقسيم المجموعة إلى قسمين أكبر وأصغر من المحور. لحل المشكل يتم اختيار العنصر الأوسط، كما يمكن اختياره عشوائيا من عنصرين متواجدين حول المركز، حيث أن عملية اختيار المحور أو الأساس تحدد أداء الخوارزمية وتأرجحها بين وقت التشغيل N*Log n وN^2 بصيغة Big O Notation.
تحسينات أخرى
عند استعمال الترتيب السريع لترتيب مجموعة ذات عناصر كبيرة، يمكن تغيير تقنية الترتيب عند الوصول إلى مجموعة جزئية غير مرتبة عدد عناصرها صغير،10 أو أقل. الترتيب بالاختيار مناسب في هذه الحالة.
الخوارزمية

ترتيب سريع هي خوارزمية فرق تسد . يقوم أولاً بتقسيم مصفوفة الإدخال إلى مصفوفتين فرعيتين أصغر: العناصر المنخفضة والعناصر العالية. ثم يقوم بفرز المصفوفات الفرعية بشكل متكرر. خطوات الترتيب السريع الموضعي هي:
- اختر عنصرًا يسمى المحور من المصفوفة.
- التقسيم : أعد ترتيب المصفوفة بحيث تأتي جميع العناصر ذات القيم الأقل من المحور قبل المحور، بينما تأتي جميع العناصر ذات القيم الأكبر من المحور بعده (يمكن أن تذهب القيم المتساوية في أي اتجاه). بعد هذا التقسيم، يكون المحور في موضعه النهائي. هذا يسمى عملية التقسيم .
- قم بتطبيق الخطوات المذكورة أعلاه بشكل متكرر على المصفوفة الفرعية للعناصر ذات القيم الأصغر وبشكل منفصل على المصفوفة الفرعية للعناصر ذات القيم الأكبر.
الحالة الأساسية للتكرار هي مصفوفات بحجم صفر أو واحد، وهي مرتبة حسب التعريف، لذلك لا تحتاج أبدًا إلى الفرز.
يمكن إجراء خطوات التحديد والتقسيم المحوري بعدة طرق مختلفة ؛ يؤثر اختيار مخططات التنفيذ المحددة بشكل كبير على أداء الخوارزمية.
مخطط تقسيم لوموتو
يُنسب هذا المخطط إلى نيكو لوموتو وشاعه بنتلي في كتابه برمجة بيرلز وكورمين وآخرون.[19] في كتابهم مقدمة في الخوارزميات. [20] يختار هذا النظام المحور الذي يكون عادةً العنصر الأخير في المصفوفة. الخوارزمية تحتفظ بالفهرسi لأنه يمسح المصفوفة باستخدام فهرس آخرj مثل أن العناصر الموجودة فيlo خلال الصغرىi-1 (شامل) أقل من المحور والعناصر الموجودة فيi خلالj (شاملة) تساوي أو أكبر من المحور. نظرًا لأن هذا المخطط أكثر إحكاما وسهل الفهم، فإنه يستخدم بشكل متكرر في المواد التمهيدية، على الرغم من أنه أقل كفاءة من مخطط هور الأصلي، على سبيل المثال، عندما تكون جميع العناصر متساوية. [21] يتحلل هذا المخطط إلى O(n2) عندما تكون الصفيف في حالة جيدة بالفعل. [14] كانت هناك متغيرات مختلفة مقترحة لتعزيز الأداء بما في ذلك طرق مختلفة لتحديد المحور، والتعامل مع العناصر المتساوية، واستخدام خوارزميات الفرز الأخرى مثل تصنيف الإدراج للمصفوفات الصغيرة وما إلى ذلك. في سودوكود، وهو تصنيف سريع يقوم بفرز العناصر فيlo خلال الصغرىhi (شامل) للمصفوفة A على النحو التالي: [20]
algorithm quicksort(A, lo, hi) is
if lo < hi then
p := partition(A, lo, hi)
quicksort(A, lo, p - 1)
quicksort(A, p + 1, hi)
algorithm partition(A, lo, hi) is
pivot := A[hi]
i := lo
for j := lo to hi do
if A[j] < pivot then
swap A[i] with A[j]
i := i + 1
swap A[i] with A[hi]
return i
يتم فرز المجموعة بأكملها بواسطةquicksort(A, 0, length(A) - 1) .
مخطط تقسيم هور
يستخدم مخطط التقسيم الأصلي الذي وصفه توني هور مؤشرين يبدأان في نهايات المصفوفة التي يتم تقسيمها، ثم ينتقلان باتجاه بعضهما البعض، حتى يكتشفوا انعكاسًا: زوج من العناصر، واحد أكبر من أو يساوي المحور، واحد أقل من أو يساوي، بترتيب خاطئ بالنسبة لبعضها البعض. ثم يتم تبديل العناصر المقلوبة. [22] عندما تلتقي المؤشرات، تتوقف الخوارزمية وتعيد الفهرس النهائي. يعتبر مخطط هور أكثر كفاءة من مخطط تقسيم لوموتو لأنه يقوم بإجراء مقايضات أقل بثلاث مرات في المتوسط، كما أنه ينشئ أقسامًا فعالة حتى عندما تكون جميع القيم متساوية. [14] مثل مخطط تقسيم لوموتو، سيؤدي تقسيم هور أيضًا إلى تدهور ترتيب سريع إلى O(n2) للمدخلات التي تم فرزها بالفعل، إذا تم اختيار المحور ليكون العنصر الأول أو الأخير. مع وجود العنصر الأوسط كمحور، ينتج عن البيانات المصنفة (تقريبًا) عدم وجود مقايضات في أقسام متساوية الحجم تؤدي إلى أفضل سلوك حالة لـ ترتيب سريع، أي O(n log(n)) . مثل الآخرين، لا ينتج تقسيم هور نوعًا مستقرًا. في هذا المخطط، لا يكون الموقع النهائي للمحور بالضرورة في الفهرس الذي يتم إرجاعه، حيث يمكن أن ينتهي المحور والعناصر التي تساوي المحور في أي مكان داخل القسم بعد خطوة القسم، وقد لا يتم فرزها حتى الحالة الأساسية لـ يتم الوصول إلى القسم الذي يحتوي على عنصر واحد عبر العودية. المقطعان التاليان اللذان تكررهما الخوارزمية الرئيسية هما(lo..p) (العناصر ≤ المحور) و(p+1..hi) (العناصر ≥ المحور) مقابل(lo..p-1) و(p+1..hi) كما في مخطط لوموتو. ومع ذلك، فإن خوارزمية التقسيم تضمن lo ≤ p < hi مما يعني أن كلا القسمين الناتجين غير فارغين، وبالتالي لا يوجد خطر من التكرار اللانهائي. في الكود الزائف، [20]
algorithm quicksort(A, lo, hi) is
if lo < hi then
p := partition(A, lo, hi)
quicksort(A, lo, p)
quicksort(A, p + 1, hi)
algorithm partition(A, lo, hi) is
pivot := A[ floor((hi + lo) / 2) ]
i := lo - 1
j := hi + 1
loop forever
do
i := i + 1
while A[i] < pivot do
j := j - 1
while A[j] > pivot
if i ≥ j then
return j
swap A[i] with A[j]
يتم تقريب التقسيم المحوري لأسفل، كما هو موضح هنا بواسطة دالة الأرضية ؛ [23] هذا يتجنب استخدام A [hi] كمحور، مما قد يؤدي إلى تكرار لا نهائي.
يتم فرز المجموعة بأكملها حسبquicksort(A, 0, length(A) - 1) .
اختيار المحور
في الإصدارات المبكرة جدًا من الترتيب السريع، غالبًا ما يتم اختيار العنصر الموجود في أقصى اليسار كعنصر محوري. لسوء الحظ، يتسبب هذا في سلوك أسوأ حالة على المصفوفات التي تم فرزها بالفعل، وهي حالة استخدام شائعة إلى حد ما. تم حل المشكلة بسهولة عن طريق اختيار إما فهرس عشوائي للمحور، أو اختيار المؤشر الأوسط للقسم أو (خاصة للأقسام الأطول) باختيار وسيط العنصر الأول والمتوسط والأخير من القسم للمحور (على النحو الموصى به من قبل عالم الكمبيوتر روبرت سيدجويك). [24] تقاوم قاعدة "الوسيط من ثلاثة" حالة الإدخال المصنف (أو الفرز العكسي)، وتعطي تقديرًا أفضل للمحور الأمثل (الوسيط الحقيقي) بدلاً من تحديد أي عنصر فردي، في حالة عدم وجود معلومات حول ترتيب الإدخال معروف.
مقتطف رمز متوسط من ثلاثة لقسم لوموتو:
mid := ⌊(lo + hi) / 2
⌋ if A[mid] < A[lo]
swap A[lo] with A[mid]
if A[hi] < A[lo]
swap A[lo] with A[hi]
if A[mid] < A[hi]
swap A[mid] with A[hi]
pivot := A[hi]
يضع الوسيط في A[hi] أولاً، ثم يتم استخدام القيمة الجديدة لـ A[hi] للمحور، كما هو الحال في الخوارزمية الأساسية المعروضة أعلاه.
على وجه التحديد، العدد المتوقع من المقارنات اللازمة لفرز n العناصر (انظر § تحليل الفرز السريع العشوائي) مع الاختيار المحوري العشوائي هو 1.386 n log n . يؤدي متوسط ثلاثة محاور إلى خفض هذا إلى معامل ذو الحدينn, 2 ≈ 1.188 n log n، على حساب زيادة قدرها ثلاثة بالمائة في العدد المتوقع من المقايضات. [11] قاعدة تمحور أقوى، للمصفوفات الأكبر، هي اختيار التاسع، وهو متوسط تكراري من ثلاثة (Mo3)، كما هو محدد. [11]
ninther(a) = median(Mo3(first ⅓ of a), Mo3(middle ⅓ of a), Mo3(final ⅓ of a))
يعد تحديد عنصر محوري أمرًا معقدًا أيضًا بسبب وجود تجاوز عدد صحيح . إذا كانت مؤشرات الحدود للمصفوفة الفرعية التي يتم فرزها كبيرة بدرجة كافية، فإن التعبير الساذج للفهرس الأوسط، (lo + hi)/2، سيؤدي إلى تجاوز التدفق وتوفير فهرس محوري غير صالح. يمكن التغلب على ذلك باستخدام، على سبيل المثال، lo + (hi−lo)/2 لفهرسة العنصر الأوسط، على حساب حسابي أكثر تعقيدًا. تظهر مشكلات مماثلة في بعض الطرق الأخرى لاختيار العنصر المحوري.
عناصر متكررة
باستخدام خوارزمية التقسيم مثل مخطط تقسيم لوموتو الموضح أعلاه (حتى إذا كان يختار قيمًا محورية جيدة)، يُظهر الترتيب السريع أداءً ضعيفًا للمدخلات التي تحتوي على العديد من العناصر المتكررة. تظهر المشكلة بوضوح عندما تكون جميع عناصر الإدخال متساوية: في كل تكرار، يكون القسم الأيسر فارغًا (لا توجد قيم إدخال أقل من المحور)، ويكون القسم الأيمن قد انخفض بمقدار عنصر واحد فقط (تتم إزالة المحور). وبالتالي، فإن مخطط تقسيم لوموتو يأخذ الوقت من الدرجة الثانية لفرز مجموعة من القيم متساوية. ومع ذلك، باستخدام خوارزمية التقسيم مثل نظام تقسيم هور، تؤدي العناصر المتكررة عمومًا إلى تقسيم أفضل، وعلى الرغم من إمكانية حدوث مبادلات غير ضرورية للعناصر المساوية للمحور، فإن وقت التشغيل ينخفض بشكل عام مع زيادة عدد العناصر المتكررة (مع ذاكرة التخزين المؤقت تقليل حجم المبادلة). في حالة تساوي جميع العناصر، يقوم مخطط تقسيم هور بتبديل العناصر دون داع، ولكن التقسيم نفسه هو أفضل حالة، كما هو مذكور في قسم قسم هور أعلاه.
لحل مشكلة مخطط تقسيم لوموتو (تسمى أحيانًا مشكلة العلم الوطني الهولندي [11] )، يمكن استخدام روتين بديل لتقسيم الوقت الخطي يفصل القيم إلى ثلاث مجموعات: القيم الأقل من المحور، والقيم التي تساوي المحور، والقيم الأكبر من المحور. (يسمي بنتلي وماكلروي هذا "قسمًا سمينًا" وقد تم تنفيذه بالفعل فيqsort من الإصدار 7 يونكس . [11] ) القيم التي تساوي المحور تم فرزها بالفعل، لذا يجب فرز الأقسام الأصغر من والأكبر من فقط بشكل متكرر. في الكود الزائف، تصبح خوارزمية الفرز السريع
algorithm quicksort(A, lo, hi) is
if lo < hi then
p := pivot(A, lo, hi)
left, right := partition(A, p, lo,
hi) // note: multiple return values
quicksort(A, lo, left - 1)
quicksort(A, right + 1, hi)
يقوم partition بإرجاع المؤشرات إلى العنصر الأول ("أقصى اليسار") وإلى العنصر الأخير ("أقصى اليمين") من القسم الأوسط. كل عنصر من القسم يساوي p وبالتالي يتم فرزها. وبالتالي، لا يلزم تضمين عناصر القسم في الاستدعاءات المتكررة ترتيب سريع .
تحدث أفضل حالة للخوارزمية الآن عندما تكون جميع العناصر متساوية (أو يتم اختيارها من مجموعة صغيرة من k ≪ n ). في حالة كل العناصر المتساوية، سينفذ التصنيف السريع المعدل مكالمتين متتاليتين فقط على المصفوفات الفرعية الفارغة، وبالتالي ينتهي في الوقت الخطي (بافتراض أن partition الفرعي لا يستغرق أكثر من الوقت الخطي).
التحسينات
هناك نوعان من التحسينات المهمة الأخرى، التي اقترحها سيدجويك والمستخدمة على نطاق واسع في الممارسة، هي: [25]
- للتأكد من استخدام مساحة O(log n) على الأكثر، قم بالتكرار أولاً في الجانب الأصغر من القسم، ثم استخدم استدعاء الذيل للتكرار في الجانب الآخر، أو قم بتحديث المعلمات بحيث لا تتضمن بعد الآن الجانب الأصغر المصنف الآن، وكرر لفرز الجانب الأكبر.
- عندما يكون عدد العناصر أقل من بعض العتبة (ربما عشرة عناصر)، قم بالتبديل إلى خوارزمية فرز غير متكررة مثل فرز الإدراج الذي يؤدي إلى مقايضات أو مقارنات أو عمليات أخرى على مثل هذه المصفوفات الصغيرة. ستختلف "العتبة" المثالية بناءً على تفاصيل التنفيذ المحدد.
- متغير أقدم من التحسين السابق: عندما يكون عدد العناصر أقل من الحد k، توقف ببساطة، ثم بعد معالجة المصفوفة بأكملها، قم بإجراء فرز للإدراج عليها. وقف الأوراق في وقت مبكر العودية -بترتيب k بالمجموعة، وهذا يعني أن كل عنصر في معظم المناصب k بعيدا عن موقفها النهائي فرزها. في هذه الحالة، يستغرق فرز O(kn) لإنهاء الفرز، والذي يكون خطيًا إذا كان k ثابتًا. [26] [19] :117 مقارنة بتحسين "العديد من الأنواع الصغيرة"، قد ينفذ هذا الإصدار تعليمات أقل، ولكنه يستخدم دون المستوى الأمثل لذاكرة التخزين المؤقت في أجهزة الكمبيوتر الحديثة. [27]
التوازي
صيغة ترتيب سريع الخاصة بفرق تسد تجعلها قابلة للتوازي باستخدام توازي المهام . يتم إنجاز خطوة التقسيم من خلال استخدام خوارزمية مجموع البادئة المتوازية لحساب فهرس لكل عنصر مصفوفة في قسمها من المصفوفة المقسمة. [28] [29] بالنظر إلى مجموعة من الحجم n، تقوم خطوة التقسيم بتنفيذ O(n) العمل في O(log n) الوقت وتتطلب O(n) مساحة خدش إضافية. بعد تقسيم المصفوفة، يمكن فرز القسمين بشكل متكرر على التوازي. O(log² n) المتوازي يفرز مجموعة من الحجم n في O(n log n) تعمل في O(log² n) الوقت باستخدام O(n) مساحة إضافية.
لدى ترتيب سريع بعض العيوب عند مقارنتها بخوارزميات الفرز البديلة، مثل دمج الفرز، مما يعقد موازنتها الفعالة. يؤثر عمق شجرة الانقسام والقهر في التصنيف السريع بشكل مباشر على قابلية توسيع الخوارزمية، ويعتمد هذا العمق بشكل كبير على اختيار الخوارزمية للمحور. بالإضافة إلى ذلك، من الصعب موازاة خطوة التقسيم بكفاءة في مكانها. يعمل استخدام مساحة التسويد على تبسيط خطوة التقسيم، ولكنه يزيد من أثر ذاكرة الخوارزمية والنفقات العامة الثابتة.
يمكن أن تحقق خوارزميات الفرز المتوازي الأخرى الأكثر تعقيدًا حدودًا زمنية أفضل. [30] على سبيل المثال، في عام 1991، وصف ديفيد باورز الفرز السريع المتوازي (وفرز الجذر المرتبط) الذي يمكن أن يعمل في وقت O(log n) على القراءة المتزامنة والكتابة المتزامنة (CRCW) وآلة الوصول العشوائي المتوازية (PRAM) مع n معالجات بواسطة أداء التقسيم ضمنيًا. [31]
التحليل الرسمي
تحليل الحالة الأسوأ
يحدث القسم غير المتوازن عندما تكون إحدى القوائم الفرعية التي يتم إرجاعها بواسطة إجراء التقسيم بحجم n − 1 . [32] قد يحدث هذا إذا كان المحور هو أصغر أو أكبر عنصر في القائمة، أو في بعض عمليات التنفيذ (على سبيل المثال، نظام تقسيم لوموتو كما هو موضح أعلاه) عندما تكون جميع العناصر متساوية.
إذا حدث هذا بشكل متكرر في كل قسم، فإن كل مكالمة متكررة تعالج قائمة بحجم أقل من القائمة السابقة. وبالتالي، يمكننا إجراء n − 1 قبل أن نصل إلى قائمة الحجم 1. هذا يعني أن شجرة الاستدعاء عبارة عن سلسلة خطية من المكالمات المتداخلة n − 1 i عشر دعوة يفعل O(n − i) العمل للقيام به القسم، و ، وذلك في هذه الحالة فرز سريع يأخذ O(n²) وقت O(n²)

تحليل أفضل حالة
في الحالة الأكثر توازناً، في كل مرة نقوم فيها بإجراء قسم، نقسم القائمة إلى قسمين متساويين تقريبًا. هذا يعني أن كل مكالمة متكررة تعالج قائمة من نصف الحجم. ونتيجة لذلك، يمكننا أن نجعل فقط log2 n المتداخلة المكالمات قبل أن نصل إلى قائمة حجم 1. هذا يعني أن عمق شجرة الاستدعاء هو log2 n . لكن لا يوجد مكالمتان على نفس المستوى من شجرة الاستدعاء تعالج نفس الجزء من القائمة الأصلية ؛ وبالتالي، فإن كل مستوى من المكالمات يحتاج فقط إلى وقت O(n) معًا (كل مكالمة لها بعض الحمل الثابت، ولكن نظرًا لوجود O(n) في كل مستوى، يتم تضمين ذلك في O(n) عامل). والنتيجة هي أن الخوارزمية تستخدم الوقت O(n log n) فقط.
تحليل متوسط الحالة
لفرز مجموعة من العناصر المتميزة n O(n log n) في التوقع، بمتوسط كل n! تباديل عناصر n باحتمالية متساوية . نسرد هنا ثلاثة أدلة شائعة لهذا الادعاء تقدم رؤى مختلفة حول طريقة عمل الترتيب السريع.
باستخدام النسب المئوية
إذا كان لكل محور مرتبة في مكان ما في منتصف 50 بالمائة، أي بين 25 بالمائة و 75 بالمائة، فإنه يقسم العناصر بنسبة 25٪ على الأقل و 75٪ على الأكثر على كل جانب. إذا تمكنا من اختيار هذه المحاور باستمرار، فسنضطر فقط إلى تقسيم القائمة على الأكثر مرات قبل الوصول إلى قوائم الحجم 1، مما ينتج عنه خوارزمية O(n log n)

عندما يكون الإدخال تبديلًا عشوائيًا، يكون للمحور ترتيب عشوائي، وبالتالي لا يمكن ضمان أن يكون في منتصف 50 بالمائة. ومع ذلك، عندما نبدأ من التقليب العشوائي، في كل استدعاء تكراري، يكون للمحور ترتيب عشوائي في قائمته، وبالتالي فهو في منتصف 50 بالمائة تقريبًا نصف الوقت. هذا جيد بما فيه الكفاية. تخيل أن عملة انقلبت: الرؤوس تعني أن رتبة المحور في منتصف 50 بالمائة، والذيل يعني أنه ليس كذلك. تخيل الآن أن العملة انقلبت مرارًا وتكرارًا حتى تحصل على شكل k . على الرغم من أن هذا قد يستغرق وقتًا طويلاً، إلا أنه في المتوسط 2k فقط، واحتمال عدم حصول العملة المعدنية على رؤوس k 100k أمر غير محتمل للغاية (يمكن جعل هذا صارمًا باستخدام حدود تشيرنوف). من خلال نفس الوسيطة، سينتهي عودية ترتيب سريع في المتوسط عند عمق مكالمة فقط . ولكن إذا كان متوسط عمق المكالمة هو O(log n)، وكل مستوى من عمليات شجرة الاستدعاء في معظم n العناصر، فإن إجمالي مقدار العمل المنجز في المتوسط هو المنتج O(n log n) . لا يتعين على الخوارزمية التحقق من أن المحور يقع في النصف الأوسط - إذا ضربناه بأي جزء ثابت من المرات، فهذا يكفي للتعقيد المطلوب.

باستخدام التكرارات
طريقة بديلة هي إنشاء علاقة تكرار T(n)، الوقت اللازم لفرز قائمة بالحجم n . في أكثر الحالات غير المتوازنة، تتضمن مكالمة الفرز السريع الفردية O(n) العمل بالإضافة إلى مكالمتين متكررتين على قوائم الحجم 0 و n−1، وبالتالي فإن علاقة التكرار هي

هذه هي نفس العلاقة بالنسبة لفرز الإدراج وفرز التحديد، وهي تحل أسوأ حالة T(n) = O(n²) .
في الحالة الأكثر توازناً، تتضمن مكالمة الفرز السريع الفردية عمل O(n) بالإضافة إلى مكالمتين متكررتين على قوائم بحجم n/2، وبالتالي فإن علاقة التكرار هي
- تخبرنا النظرية الرئيسية لتكرار فرق تسد T(n) = O(n log n) .
- يتبع مخطط إثبات رسمي لتعقيد الوقت المتوقع O(n log n) افترض أنه لا توجد نسخ مكررة حيث يمكن التعامل مع التكرارات بوقت خطي قبل المعالجة وبعدها، أو اعتبار الحالات أسهل من التي تم تحليلها. عندما يكون الإدخال عبارة عن تبديل عشوائي، فإن رتبة المحور تكون عشوائية منتظمة من 0 إلى n − 1 . ثم يكون للأجزاء الناتجة من القسم أحجام i و n − i − 1، وأنا عشوائي منتظم من 0 إلى n − 1 . لذلك، عند حساب المتوسط على جميع الانقسامات الممكنة مع ملاحظة أن عدد المقارنات للقسم هو n − 1، يمكن تقدير متوسط عدد المقارنات عبر جميع تباديل تسلسل الإدخال بدقة عن طريق حل علاقة التكرار:




-
- يعطي حل التكرار C(n) = 2n ln n ≈ 1.39n log₂ n .


هذا يعني أن الترتيب السريع، في المتوسط، يؤدي فقط نحو 39٪ أسوأ مما كان عليه في أفضل حالاته. وبهذا المعنى، فهي أقرب إلى الحالة الأفضل من الحالة الأسوأ. لا يمكن لفرز المقارنة استخدام مقارنات أقل من log₂(n!) في المتوسط لفرز n العناصر (كما هو موضح في مقالة فرز المقارنة ) وفي حالة n الكبيرة، ينتج عن تقريب ستيرلينغ log₂(n!) ≈ n(log₂ n − log₂ e)، لذا فإن الترتيب السريع ليس أسوأ بكثير من نوع المقارنة المثالي. يعد متوسط وقت التشغيل السريع هذا سببًا آخر للهيمنة العملية للفرز السريع على خوارزميات الفرز الأخرى.
استخدام شجرة بحث ثنائية
تتوافق شجرة البحث الثنائية التالية (BST) مع كل تنفيذ للفرز السريع: المحور الأولي هو العقدة الجذرية ؛ محور النصف الأيسر هو جذر الشجرة الفرعية اليسرى، ومحور النصف الأيمن هو جذر الشجرة الفرعية اليمنى، وهكذا. عدد مقارنات تنفيذ الفرز السريع يساوي عدد المقارنات أثناء إنشاء BST من خلال سلسلة من عمليات الإدراج. لذا، فإن متوسط عدد المقارنات للفرز السريع العشوائي يساوي متوسط تكلفة إنشاء BST عند إدراج القيم تشكيل تبديل عشوائي.

ضع في اعتبارك BST تم إنشاؤه عن طريق إدراج تسلسل من القيم التي تشكل التقليب العشوائي. دع C تشير إلى تكلفة إنشاء BST. نملك ، أين هو متغير عشوائي ثنائي يعبر عما إذا كان أثناء إدخال كانت هناك مقارنة .




حسب خطية التوقع، القيمة المتوقعة من C هو .


إصلاح i و j<i . القيم بمجرد الفرز، حدد فترات j+1 الملاحظة الهيكلية الأساسية هي أن بالمقارنة مع في الخوارزمية إذا وفقط إذا يقع داخل أحد الفترتين المتجاورتين لـ .

لاحظ ذلك منذ ذلك الحين هو تبديل عشوائي، هو أيضًا تبديل عشوائي، لذا فإن الاحتمال مجاور ل هو بالضبط .


ننتهي بحساب قصير:

تعقيد الفضاء
المساحة التي يستخدمها الترتيب السريع تعتمد على الإصدار المستخدم. يحتوي الإصدار الموضعي من الترتيب السريع على تعقيد مساحة O(log n)، حتى في أسوأ الحالات، عندما يتم تنفيذه بعناية باستخدام الاستراتيجيات التالية:
- يتم استخدام التقسيم الموضعي. يتطلب هذا القسم غير المستقر مساحة O(1)
- بعد التقسيم، يتم فرز القسم الذي يحتوي على أقل عدد من العناصر (بشكل متكرر) أولاً، مما يتطلب مساحة O(log n) ثم يتم فرز القسم الآخر باستخدام تكرار الذيل أو التكرار، والذي لا يضيف إلى مكدس الاستدعاءات. هذه الفكرة، كما تمت مناقشتها أعلاه، وصفها روبرت سيدجويك، وتحافظ على عمق المكدس المحدد بـ O(log n) . [33] [26]
ترتيب سريع مع التقسيم الموضعي وغير المستقر يستخدم مساحة إضافية ثابتة فقط قبل إجراء أي مكالمة متكررة. يجب أن يقوم ترتيب سريع بتخزين قدر ثابت من المعلومات لكل مكالمة متكررة متداخلة. نظرًا لأن أفضل حالة تجعل على الأكثر استدعاءات متكررة متداخلة O(log n)، فإنها تستخدم مساحة O(log n) ومع ذلك، من دون حيلة سيدجويك للحد من المكالمات متكررة، في أسوأ حالة فرز سريع يمكن أن تجعل O(n) دعوات متكررة متداخلة والحاجة O(n) الفضاء مساعدة.
من وجهة نظر التعقيد قليلاً، لا تستخدم المتغيرات مثل lo و hi مساحة ثابتة ؛ يستغرق الأمر O(log n) bits للفهرسة في قائمة n من العناصر. نظرًا لوجود مثل هذه المتغيرات في كل إطار مكدس، فإن الترتيب السريع باستخدام خدعة وبرت سيدجويك يتطلب O((log n)²) بت من المساحة. متطلبات المساحة هذه ليست سيئة للغاية، على الرغم من ذلك، لأنه إذا كانت القائمة تحتوي على عناصر مميزة، فستحتاج على الأقل إلى O(n log n) بت من المساحة.
إصدار آخر، أقل شيوعًا، غير موجود، من الترتيب السريع يستخدم O(n) لتخزين العمل ويمكنه تنفيذ فرز مستقر. تسمح مساحة التخزين العاملة بتقسيم مصفوفة الإدخال بسهولة بطريقة مستقرة ثم نسخها مرة أخرى إلى مصفوفة الإدخال لإجراء مكالمات متكررة متتالية. لا يزال تحسين روبرت سيدجويك مناسبًا.
ملخص خطوات الخوارزمية
- أولا : نقوم باختيار المحور أو الأساس
- ثانيا : نقوم بإنشاء ثلاث مصفوفات واحد G تحتوي على العناصر التي هي أكبر من المحور، الثانية E وهي تحتوي على عناصر التي هي مساوية
للمحور، الثالثة وهي L وهي تحتوي على العناصر التي هي اقل من المحور
- ثالثا : نقوم بعمل استدعاء ذاتي على المصفوفة L، G
- رابعا : عند الوصول إلى مرحلة تكون فيها عدد العناصر في المصوفة اقل من 2 أي واحد تكون عناصر مصفوفة مرتبة لانها تحتوي على عنصر
واحد فقط !
- خامسا: نقوم بخطوة التجميع وهي تتصمن جمع المصوفات الثلاث في مصفوفة جديدة بترتيب حيث نضع المصفوفة L ثم E ثم G فيصبح لدينا مصموفة
تحتوي على العناصر مرتبة
مثال
algorithm ترتيب سريع(A, lo, hi) is if lo < hi then pp:= partition(A, lo, hi) ترتيب سريع(A, lo, p – 1) ترتيب سريع(A, p + 1, hi)
algorithm partition(A, lo, hi) is pivot := A[hi] i := lo // place for swapping for j := lo to hi – 1 do if A[j] ≤ pivot then swap A[i] with A[j] i := i + 1 swap A[i] with A[hi] return i
يتم ترتيب المصفوفة باستدعاء quicksort(A, 1, length(A)).
العلاقة بالخوارزميات الأخرى
ترتيب سريع هو نسخة محسّنة للمساحة لفرز الشجرة الثنائية . بدلاً من إدراج العناصر بشكل تسلسلي في شجرة صريحة، يقوم التصنيف السريع بتنظيمها بشكل متزامن في شجرة تتضمنها المكالمات المتكررة. تقوم الخوارزميات بإجراء نفس المقارنات تمامًا، ولكن بترتيب مختلف. من الخصائص المرغوبة غالبًا لخوارزمية الفرز الاستقرار - حيث لا يتم تغيير ترتيب العناصر التي تقارن التساوي، مما يسمح بالتحكم في ترتيب جداول مالتيكاي(مثل قوائم الدليل أو المجلدات) بطريقة طبيعية. هذه المنشأة السياحية من الصعب الحفاظ عليها في الموقع فرز سريع (أو في مكان) (أي استخدامات فقط مساحة إضافية المستمر لمؤشرات ومخازن، O(log n) مساحة إضافية لإدارة العودية الصريحة أو الضمنية). بالنسبة للفرز السريع المتغير الذي يتضمن ذاكرة إضافية بسبب التمثيلات باستخدام المؤشرات (مثل القوائم أو الأشجار) أو الملفات (القوائم الفعالة)، فمن التافه الحفاظ على الاستقرار. تميل هياكل البيانات الأكثر تعقيدًا أو المرتبطة بالقرص إلى زيادة تكلفة الوقت، مما يؤدي بشكل عام إلى زيادة استخدام الذاكرة الافتراضية أو القرص.
المنافس المباشر للفرز السريع هو كومة. وقت تشغيل هيبسورت هو O(n log n)، لكن متوسط وقت تشغيل هيبسورت يُعتبر عادةً أبطأ من الترتيب السريع في المكان. [31] هذه النتيجة قابلة للنقاش. تشير بعض المنشورات إلى عكس ذلك. [34] [35] إنتروسورت هو أحد أنواع الفرز السريع الذي يتحول إلى الترتيب المتراكم عند اكتشاف حالة سيئة لتجنب وقت تشغيل الترتيب السريع في أسوأ الحالات.
يتنافس ترتيب سريع أيضًا مع فرز الدمج، وهو خوارزمية فرز O(n log n) يعد ميرجسورت نوعًا مستقرًا، على عكس الترتيب السريع في المكان القياسي والفرز المتراكم، ويتميز بأداء ممتاز في أسوأ الحالات. العيب الرئيسي لفرز الدمج هو أنه عند التشغيل على المصفوفات، تتطلب التطبيقات الفعالة O(n)، في حين أن متغير الفرز السريع مع التقسيم الموضعي والتكرار الخلفي يستخدم مساحة O(log n)
يعمل ميرجسورت بشكل جيد جدًا على القوائم المرتبطة، ولا يتطلب سوى قدر صغير وثابت من التخزين الإضافي. على الرغم من أنه يمكن تنفيذ الفرز السريع كنوع مستقر باستخدام القوائم المرتبطة، إلا أنه غالبًا ما يعاني من خيارات محورية ضعيفة بدون وصول عشوائي. يعد ميرجسورت أيضًا الخوارزمية المفضلة للفرز الخارجي لمجموعات البيانات الكبيرة جدًا المخزنة على وسائط بطيئة الوصول مثل تخزين القرص أو التخزين المتصل بالشبكة .
يشبه الفرز دلو مع دلاء إلى حد كبير الفرز السريع ؛ المحور في هذه الحالة هو بشكل فعال القيمة الموجودة في منتصف نطاق القيمة، والتي تعمل بشكل جيد في المتوسط للمدخلات الموزعة بشكل موحد.
التمحور القائم على الاختيار
A اختيار خوارزمية يختار k أصغر من قائمة بأرقام عشر. هذه مشكلة أسهل بشكل عام من الفرز. تعمل خوارزمية اختيار بسيطة ولكنها فعالة بنفس طريقة الترتيب السريع تقريبًا، وبالتالي تُعرف باسم التحديد السريع . الفرق هو أنه بدلاً من إجراء مكالمات متكررة على كلتا القائمتين الفرعيتين، فإنه يقوم فقط بإجراء مكالمة متكررة ذيل واحدة في القائمة الفرعية التي تحتوي على العنصر المطلوب. يقلل هذا التغيير من متوسط التعقيد إلى الوقت الخطي أو O(n)، وهو الأمثل للاختيار، لكن خوارزمية الفرز لا تزال O(n2) .
يختار أحد متغيرات التحديد السريع، وهو متوسط خوارزمية المتوسطات، المحاور بدقة أكبر، مما يضمن أن المحاور قريبة من منتصف البيانات (بين النسب المئوية 30 و 70)، وبالتالي تضمن الوقت الخطي - O(n) . يمكن استخدام نفس استراتيجية المحور هذه لإنشاء متغير من الترتيب السريع (متوسط الفرز السريع للوسيطات O(n log n) بوقت O(n log n) ومع ذلك، فإن النفقات العامة لاختيار المحور مهمة، لذلك لا يتم استخدام هذا بشكل عام في الممارسة.
بشكل أكثر تجريدًا، بالنظر إلى O(n)، يمكن للمرء استخدامها للعثور على المحور المثالي (الوسيط) في كل خطوة من الترتيب السريع، وبالتالي إنتاج خوارزمية فرز مع وقت تشغيل O(n log n) تكون التطبيقات العملية لهذا المتغير أبطأ إلى حد كبير في المتوسط، لكنها ذات أهمية نظرية لأنها تظهر أن خوارزمية اختيار مثالية يمكن أن تسفر عن خوارزمية فرز مثالية.
الترتيب السريع متعدد المحاور
بدلا من تقسيم إلى قسمين المصفوفات الفرعية باستخدام محور واحد، فرز سريع متعدد محور (أيضا متعدد ترتيب سريع [27] ) تقسيم مدخلاته إلى بعض رقم s من المصفوفات الفرعية باستخدام s − 1 المحاور. في حين تم النظر في حالة المحور المزدوج ( s = 3 ) بواسطة سيدجويك وآخرون بالفعل في منتصف السبعينيات، لم تكن الخوارزميات الناتجة أسرع في الممارسة العملية من الترتيب السريع "الكلاسيكي". [31] وجد تقييم عام 1999 لـ متعدد ترتيب سريع مع عدد متغير من المحاور، تم ضبطها لتحقيق الاستخدام الفعال لذاكرة التخزين المؤقت للمعالج، أنها تزيد من عدد التعليمات بحوالي 20٪، لكن نتائج المحاكاة تشير إلى أنها ستكون أكثر كفاءة مع المدخلات الكبيرة جدًا. [27] هناك نسخة من التصنيف السريع ثنائي المحور طوره ياروسلافسكي في عام 2009 [15] تبين أنها سريعة بما يكفي لضمان التنفيذ في جافا 7، حيث أن الخوارزمية القياسية لفرز مصفوفات العناصر الأولية (يتم فرز مصفوفات الكائنات باستخدام تايمسورت) . [36] تم العثور لاحقًا على أن فائدة أداء هذه الخوارزمية مرتبطة في الغالب بأداء ذاكرة التخزين المؤقت، [37] وتشير النتائج التجريبية إلى أن المتغير ثلاثي المحاور قد يؤدي بشكل أفضل على الأجهزة الحديثة. [31] [31]
فرز سريع خارجي
بالنسبة لملفات القرص، من الممكن إجراء فرز خارجي يعتمد على تقسيم مشابه للترتيب السريع. إنه أبطأ من فرز الدمج الخارجي، لكنه لا يتطلب مساحة قرص إضافية. يتم استخدام 4 مخازن، 2 للإدخال، 2 للإخراج. دع N = عدد السجلات في الملف، B = عدد السجلات لكل مخزن مؤقت، و M = N / B = عدد مقاطع المخزن المؤقت في الملف. تتم قراءة البيانات (وكتابتها) من طرفي الملف إلى الداخل. دع X تمثل المقاطع التي تبدأ في بداية الملف وتمثل Y المقاطع التي تبدأ في نهاية الملف. تتم قراءة البيانات في المخازن المؤقتة للقراءة X و Y. يتم اختيار سجل محوري ويتم نسخ السجلات الموجودة في المخازن المؤقتة X و Y بخلاف السجل المحوري إلى المخزن المؤقت للكتابة X بترتيب تصاعدي والمخزن المؤقت للكتابة Y بترتيب تنازلي على أساس المقارنة مع السجل المحوري. بمجرد ملء المخزن المؤقت X أو Y، تتم كتابته في الملف ويتم قراءة المخزن المؤقت X أو Y التالي من الملف. تستمر العملية حتى تتم قراءة جميع المقاطع ويبقى مخزن مؤقت واحد للكتابة. إذا كان هذا المخزن المؤقت عبارة عن مخزن مؤقت للكتابة على شكل X، فسيتم إلحاق السجل المحوري به وكتابة المخزن المؤقت X. إذا كان هذا المخزن المؤقت عبارة عن مخزن مؤقت للكتابة على شكل Y، يتم إرسال السجل المحوري مسبقًا إلى المخزن المؤقت Y ويتم كتابة المخزن المؤقت Y. يشكل هذا خطوة قسم واحدة للملف، ويتكون الملف الآن من ملفين فرعيين. يتم دفع / ظهور مواضع البداية والنهاية لكل ملف فرعي إلى مكدس مستقل أو المكدس الرئيسي عبر العودية. لتقييد مساحة المكدس بـ O (log2 (n))، تتم معالجة الملف الفرعي الأصغر أولاً. بالنسبة للمكدس المستقل، ادفع معلمات الملف الفرعي الأكبر إلى المكدس، ثم كرر على الملف الفرعي الأصغر. للتكرار، كرر على الملف الفرعي الأصغر أولاً، ثم كرر للتعامل مع الملف الفرعي الأكبر. بمجرد أن يكون الملف الفرعي أقل من أو يساوي 4 سجلات B، يتم فرز الملف الفرعي في مكانه عبر الترتيب السريع وكتابته. يتم الآن فرز هذا الملف الفرعي ووضعه في مكانه في الملف. تستمر العملية حتى يتم فرز جميع الملفات الفرعية ووضعها في مكانها الصحيح. متوسط عدد التمريرات على الملف هو تقريبًا 1 + ln (N + 1) / (4 B)، لكن نمط الحالة الأسوأ هو N عبر (ما يعادل O (n ^ 2) لأسوأ حالة فرز داخلي). [38]
ثلاث طرق فرز سريع للجذر
هذه الخوارزمية عبارة عن مزيج من الفرز الأساسي والترتيب السريع. اختر عنصرًا من المصفوفة (المحور) واعتبر الحرف الأول (المفتاح) من السلسلة (مالتيكاي). قسّم العناصر المتبقية إلى ثلاث مجموعات: تلك التي يكون حرفها المقابل أقل من، ويساوي، وأكبر من حرف المحور. قم بفرز الأقسام "أصغر من" و "أكبر من" بشكل متكرر على نفس الحرف. قم بفرز قسم "يساوي" بشكل متكرر حسب الحرف التالي (مفتاح). بالنظر إلى أننا نقوم بالفرز باستخدام البايتات أو الكلمات ذات الطول W، فإن أفضل حالة هي O(KN) وأسوأ حالة O(2KN) أو على الأقل O(N2) كما هو الحال بالنسبة للترتيب السريع القياسي، المعطى للمفاتيح الفريدة N<2K و K هو ثابت مخفي في جميع خوارزميات فرز المقارنة القياسية بما في ذلك الفرز السريع. هذا نوع من الترتيب السريع ثلاثي الاتجاهات حيث يمثل القسم الأوسط مصفوفة فرعية مرتبة (تافهة) من العناصر التي تساوي تمامًا المحور.
فرز الجذر السريع
تم تطويره أيضًا بواسطة باورز باعتباره خوارزمية آلة الوصول العشوائي المتوازية O(K) هذا مرة أخرى عبارة عن مزيج من فرز الجذر والفرز السريع ولكن يتم اتخاذ قرار التقسيم السريع الفرز الأيسر / الأيمن على بتات متتالية من المفتاح، وبالتالي يكون O(KN) N K -bit. تفترض جميع خوارزميات فرز المقارنة ضمنيًا النموذج متعدد التفرع مع K في Θ(log N)، كما لو كانت K أصغر، يمكننا الفرز في وقت O(N) باستخدام جدول التجزئة أو فرز عدد صحيح . إذا كانت K ≫ log N ولكن العناصر فريدة داخل O(log N)، فلن يتم النظر إلى البتات المتبقية من خلال الفرز السريع أو الفرز الأساسي السريع. إذا تعذر ذلك، فإن جميع خوارزميات فرز المقارنة سيكون لها أيضًا نفس النفقات العامة للبحث من خلال O(K) بتات عديمة الفائدة نسبيًا ولكن الفرز السريع للجذر سيتجنب أسوأ O(N2) الخاصة بالفرز السريع القياسي والفرز السريع، وسيكون أسرع في أفضل حالة من خوارزميات المقارنة هذه في ظل ظروف uniqueprefix(K) ≫ log N راجع السلطات [39] لمزيد من المناقشة حول النفقات العامة المخفية في المقارنة، والجذر والفرز المتوازي.
كتلة الترتيب السريع
في أي خوارزمية فرز قائمة على المقارنة، يتطلب تقليل عدد المقارنات تعظيم كمية المعلومات المكتسبة من كل مقارنة، مما يعني أن نتائج المقارنة غير متوقعة. يتسبب هذا في أخطاء متكررة في الفروع، مما يحد من الأداء. [31] يقوم كتلة الترتيب السريع [40] بإعادة ترتيب حسابات التصنيف السريع لتحويل الفروع غير المتوقعة إلى تبعيات البيانات . عند التقسيم، يتم تقسيم الإدخال إلى كتل متوسطة الحجم (تتناسب بسهولة مع ذاكرة التخزين المؤقت للبيانات )، ويتم ملء صفيفين بمواضع العناصر المراد تبديلها. (لتجنب الفروع الشرطية، يتم تخزين الموضع دون قيد أو شرط في نهاية المصفوفة، ويزداد فهرس النهاية إذا كانت هناك حاجة إلى مبادلة. ) يقوم التمرير الثاني بتبادل العناصر في المواضع المحددة في المصفوفات. تحتوي كلتا الحلقتين على فرع شرطي واحد فقط، وهو اختبار للإنهاء يتم إجراؤه عادةً.
فرز سريع جزئي وتزايدي
توجد العديد من المتغيرات من الترتيب السريع التي تفصل العناصر الأصغر أو الأكبر k
تعميم
اكتشف ريتشارد جيه كول و ديفيد سي. قندثيل، في عام 2004، عائلة مكونة من معلمة واحدة من خوارزميات الفرز، تسمى أنواع الأقسام، والتي تعمل في المتوسط (مع احتمالية متساوية لجميع أوامر الإدخال) على الأكثر مقارنات (قريبة من الحد الأدنى النظري للمعلومات) و عمليات؛ في أسوأ الأحوال يؤدونها المقارنات (وكذلك العمليات) ؛ هذه في مكانها، وتتطلب إضافية فقط الفراغ. تم إثبات الكفاءة العملية والتباين الأصغر في الأداء مقابل الأنواع السريعة المحسّنة (لسيارات سيدجويك وجون بنتلي - دوغلاس ماكلروي ). [41]




ملاحظات
- , نسخة محفوظة 23 أكتوبر 2017 على موقع واي باك مشين.
- Sedgewick, R. (1978). "Implementing Quicksort programs". Comm. ACM. 21 (10): 847–857. doi:10.1145/359619.359631. الوسيط
|CitationClass=تم تجاهله (مساعدة) - "Sir Antony Hoare". Computer History Museum. مؤرشف من الأصل في 3 أبريل 2015. اطلع عليه بتاريخ 22 أبريل 2015. الوسيط
|CitationClass=تم تجاهله (مساعدة) - الترتيب السريع لشارلس أنطوني هاور نسخة محفوظة 22 أبريل 2016 على موقع واي باك مشين.
- "Sir Antony Hoare". Computer History Museum. مؤرشف من الأصل في 03 أبريل 2015. اطلع عليه بتاريخ 22 أبريل 2015. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Hoare, C. A. R. (1961). "Algorithm 64: Quicksort". Comm. ACM. 4 (7): 321. doi:10.1145/366622.366644. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Skiena, Steven S. (2008). The Algorithm Design Manual. Springer. صفحة 129. ISBN 978-1-84800-069-8. مؤرشف من الأصل في 5 أغسطس 2019. الوسيط
|CitationClass=تم تجاهله (مساعدة) - C.L. Foster, Algorithms, Abstraction and Implementation, 1992, (ردمك 0122626605), p. 98
- Shustek, L. (2009). "Interview: An interview with C.A.R. Hoare". Comm. ACM. 52 (3): 38–41. doi:10.1145/1467247.1467261. الوسيط
|CitationClass=تم تجاهله (مساعدة) - "My Quickshort interview with Sir Tony Hoare, the inventor of Quicksort". Marcelo M De Barros. 2015-03-15. مؤرشف من الأصل في 7 يونيو 2020. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Bentley, Jon L.; McIlroy, M. Douglas (1993). "Engineering a sort function". Software—Practice and Experience. 23 (11): 1249–1265. doi:10.1002/spe.4380231105. مؤرشف من الأصل في 3 أغسطس 2020. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Van Emden, M. H. (1970-11-01). "Algorithms 402: Increasing the Efficiency of Quicksort". Commun. ACM. 13 (11): 693–694. doi:10.1145/362790.362803. ISSN 0001-0782. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Bentley, Jon (2007). "The most beautiful code I never wrote". In Oram, Andy; Wilson, Greg (المحررون). Beautiful Code: Leading Programmers Explain How They Think. O'Reilly Media. صفحات 30. ISBN 978-0-596-51004-6. الوسيط
|CitationClass=تم تجاهله (مساعدة) - "Quicksort Partitioning: Hoare vs. Lomuto". cs.stackexchange.com. مؤرشف من الأصل في 11 أغسطس 2019. اطلع عليه بتاريخ 03 أغسطس 2015. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Yaroslavskiy, Vladimir (2009). "Dual-Pivot Quicksort" (PDF). مؤرشف من الأصل (PDF) في 02 أكتوبر 2015. الوسيط
|CitationClass=تم تجاهله (مساعدة) - "Replacement of Quicksort in java.util.Arrays with new Dual-Pivot Quick". permalink.gmane.org. مؤرشف من الأصل في 06 نوفمبر 2018. اطلع عليه بتاريخ 03 أغسطس 2015. الوسيط
|CitationClass=تم تجاهله (مساعدة) - "Java 7 Arrays API documentation". Oracle. مؤرشف من الأصل في 12 نوفمبر 2020. اطلع عليه بتاريخ 23 يوليو 2018. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Wild, S.; Nebel, M.; Reitzig, R.; Laube, U. (2013-01-07). Engineering Java 7's Dual Pivot Quicksort Using MaLiJAn. Society for Industrial and Applied Mathematics. صفحات 55–69. doi:10.1137/1.9781611972931.5. ISBN 978-1-61197-253-5. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Jon Bentley (1999). Programming Pearls. Addison-Wesley Professional. الوسيط
|CitationClass=تم تجاهله (مساعدة) - قالب:Introduction to Algorithms
- Wild, Sebastian (2012). "Java 7's Dual Pivot Quicksort". Technische Universität Kaiserslautern. مؤرشف من الأصل في 27 يوليو 2020. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Hoare, C. A. R. (1962-01-01). "Quicksort". The Computer Journal. 5 (1): 10–16. doi:10.1093/comjnl/5.1.10. ISSN 0010-4620. مؤرشف من الأصل في 22 مايو 2014. الوسيط
|CitationClass=تم تجاهله (مساعدة) - in many languages this is the standard behavior of integer division
- Sedgewick, Robert (1 September 1998). Algorithms in C: Fundamentals, Data Structures, Sorting, Searching, Parts 1–4 (الطبعة 3). Pearson Education. ISBN 978-81-317-1291-7. مؤرشف من الأصل في 20 أغسطس 2020. الوسيط
|CitationClass=تم تجاهله (مساعدة) - qsort.c in مكتبة جنو لسي:,
- Sedgewick, R. (1978). "Implementing Quicksort programs". Comm. ACM. 21 (10): 847–857. doi:10.1145/359619.359631. الوسيط
|CitationClass=تم تجاهله (مساعدة) - LaMarca, Anthony; Ladner, Richard E. (1999). "The Influence of Caches on the Performance of Sorting". Journal of Algorithms. 31 (1): 66–104. doi:10.1006/jagm.1998.0985.
Although saving small subarrays until the end makes sense from an instruction count perspective, it is exactly the wrong thing to do from a cache performance perspective.
الوسيط|CitationClass=تم تجاهله (مساعدة) - Umut A. Acar, Guy E Blelloch, Margaret Reid-Miller, and Kanat Tangwongsan, Quicksort and Sorting Lower Bounds, Parallel and Sequential Data Structures and Algorithms. 2013. نسخة محفوظة 6 يناير 2017 على موقع واي باك مشين.
- Breshears, Clay (2012). "Quicksort Partition via Prefix Scan". Dr. Dobb's. مؤرشف من الأصل في 25 يوليو 2019. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Miller, Russ; Boxer, Laurence (2000). Algorithms sequential & parallel: a unified approach. Prentice Hall. ISBN 978-0-13-086373-7. مؤرشف من الأصل في 25 فبراير 2017. الوسيط
|CitationClass=تم تجاهله (مساعدة) - استشهاد فارغ (مساعدة)
- The other one may either have 1 element or be empty (have 0 elements), depending on whether the pivot is included in one of subpartitions, as in the Hoare's partitioning routine, or is excluded from both of them, like in the Lomuto's routine.
- Sedgewick, Robert (1 September 1998). Algorithms in C: Fundamentals, Data Structures, Sorting, Searching, Parts 1–4 (الطبعة 3). Pearson Education. ISBN 978-81-317-1291-7. مؤرشف من الأصل في 20 أغسطس 2020. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Hsieh, Paul (2004). "Sorting revisited". azillionmonkeys.com. مؤرشف من الأصل في 7 يناير 2021. الوسيط
|CitationClass=تم تجاهله (مساعدة) - MacKay, David (December 2005). "Heapsort, Quicksort, and Entropy". مؤرشف من الأصل في 01 أبريل 2009. الوسيط
|CitationClass=تم تجاهله (مساعدة) - "Arrays". Java Platform SE 7. Oracle. مؤرشف من الأصل في 12 نوفمبر 2020. اطلع عليه بتاريخ 04 سبتمبر 2014. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Wild. "Why Is Dual-Pivot Quicksort Fast?". الوسيط
|CitationClass=تم تجاهله (مساعدة);|arxiv=required (مساعدة) - An efficient external sorting with minimal space requirement - [PDF Document] نسخة محفوظة 21 يونيو 2020 على موقع واي باك مشين.
- David M. W. Powers, Parallel Unification: Practical Complexity, Australasian Computer Architecture Workshop, Flinders University, January 1995 نسخة محفوظة 2021-02-03 على موقع واي باك مشين.
- Edelkamp. "BlockQuicksort: How Branch Mispredictions don't affect Quicksort". الوسيط
|CitationClass=تم تجاهله (مساعدة);|arxiv=required (مساعدة) - Richard Cole, David C. Kandathil: "The average case analysis of Partition sorts", European Symposium on Algorithms, 14–17 September 2004, Bergen, Norway. Published: Lecture Notes in Computer Science 3221, Springer Verlag, pp. 240–251. نسخة محفوظة 11 ديسمبر 2019 على موقع واي باك مشين.
مراجع
مصادر
- Sedgewick, R. (1978). "Implementing Quicksort programs". Comm. ACM. 21 (10): 847–857. doi:10.1145/359619.359631. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Dean, B. C. (2006). "A simple expected running time analysis for randomized 'divide and conquer' algorithms". Discrete Applied Mathematics. 154: 1–5. doi:10.1016/j.dam.2005.07.005. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Hoare, C. A. R. (1961). "Algorithm 63: Partition". Comm. ACM. 4 (7): 321. doi:10.1145/366622.366642. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Hoare, C. A. R. (1961). "Algorithm 65: Find". Comm. ACM. 4 (7): 321–322. doi:10.1145/366622.366647. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Hoare, C. A. R. (1962). "Quicksort". مجلة الحاسوب. 5 (1): 10–16. doi:10.1093/comjnl/5.1.10. الوسيط
|CitationClass=تم تجاهله (مساعدة) (أعيد طبعه في هور and Jones: Essays in Computing Science، 1989.) - Musser, David R. (1997). "Introspective Sorting and Selection Algorithms". Software: Practice and Experience. 27 (8): 983–993. doi:10.1002/(SICI)1097-024X(199708)27:8<983::AID-SPE117>3.0.CO;2-#. مؤرشف من الأصل في 11 فبراير 2021. الوسيط
|CitationClass=تم تجاهله (مساعدة) - دونالد كنوث . فن برمجة الكمبيوتر، المجلد 3: الفرز والبحث، الطبعة الثالثة. أديسون ويسلي، 1997.(ردمك 0-201-89685-0)رقم ISBN 0-201-89685-0 . الصفحات 113-122 من القسم 5.2.2: الفرز عن طريق التبادل.
- توماس إتش كورمين، تشارلز إي ليسيرسون، رونالد إل ريفيست، وكليفورد شتاين . مقدمة في الخوارزميات، الطبعة الثانية. مطبعة معهد ماساتشوستس للتكنولوجيا ومكجرو هيل، 2001.(ردمك 0-262-03293-7)رقم ISBN 0-262-03293-7 . الفصل 7: ترتيب سريع، ص. 145–164.
- فارون مولر . تحليل ترتيب سريع . CS 332: تصميم الخوارزميات. قسم علوم الحاسوب، جامعة سوانسي .
- Martínez, C.; Roura, S. (2001). "Optimal Sampling Strategies in Quicksort and Quickselect". SIAM J. Comput. 31 (3): 683–705. doi:10.1137/S0097539700382108. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Bentley, J. L.; McIlroy, M. D. (1993). "Engineering a sort function". Software: Practice and Experience. 23 (11): 1249–1265. doi:10.1002/spe.4380231105. الوسيط
|CitationClass=تم تجاهله (مساعدة)
روابط خارجية
- "Animated Sorting Algorithms: Quick Sort". مؤرشف من الأصل في 02 مارس 2015. اطلع عليه بتاريخ 25 نوفمبر 2008. الوسيط
|CitationClass=تم تجاهله (مساعدة) - عرض رسومي - "Animated Sorting Algorithms: Quick Sort (3-way partition)". مؤرشف من الأصل في 06 مارس 2015. اطلع عليه بتاريخ 25 نوفمبر 2008. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Open Data Structures - القسم 11.1.2 - ترتيب سريع، بات مورين
- رسم توضيحي تفاعلي لـ ترتيب سريع، مع تجول التعليمات البرمجية
 بوابة علم الحاسوب
بوابة علم الحاسوب بوابة خوارزميات
بوابة خوارزميات بوابة عقد 1960
بوابة عقد 1960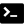 بوابة برمجة الحاسوب
بوابة برمجة الحاسوب بوابة تقنية المعلومات
بوابة تقنية المعلومات بوابة رياضيات
بوابة رياضيات
