زاحف الشبكة
زاحف الشبكة أو زاحف الويب (بالإنجليزية: Web crawler) هو برنامج كمبيوتر يقوم بتصفح الشبكة العالمية بطريقة منهجية وآلية ومنظمة. هناك مصطلحات أخرى لزواحف الشبكة مثل النمل والمفهرس التلقائي، والبوت.[1]، وعناكب الشبكة [2]، أو آليات الشبكة.[2] وهذه العملية تسمى الزحف على الشبكة أو العنكبة.
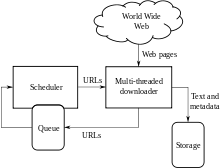
كثير من المواقع، وبخاصة محركات البحث، تستخدم العنكبة كوسيلة لتوفير بيانات حديثة. وزواحف الشبكة تستخدم أساسا لإنشاء نسخ من جميع الصفحات التي يتم زيارتها لكى يفهرسها محرك البحث في وقت لاحق ويحمل الصفحات أثناء عمليات البحث بسرعة. ويمكن أيضا أن تستخدم الزواحف لاتمام مهام الصيانة على موقع علي الشبكة، مثل التحقق من صحة الروابط أو تعليمات لغة تحرير النص الفائق البرمجية. أيضا، يمكن استخدام الزواحف لجمع أنواع محددة من المعلومات من صفحات الشبكة، مثل حصاد عناوين البريد الإلكتروني (عادة لارسال رسائل غير المرغوب فيها).
وزاحف الشبكة هو أحد أنواع البوتات، أو وكلاء البرامج. بشكل عام، يبدأ زاحف الشبكة بقائمة من العناوين المرغوب في زيارتها، وتدعى هذه القائمة بالبذور. عندما يزور الزاحف هذه العناوين، فإنه يحدد كافة الارتباطات التشعبية في الصفحة ويضيفها إلى قائمة العناوين المطلوب زيارتها، وتدعى حدود الزحف. وتتم زيارة عناوين حدود الزحف بشكل متكرر وفقا لمجموعة من السياسات.
بسبب الحجم الكبير يمكن للزاحف تحميل جزء صغير فقط من صفحات الشبكة في غضون فترة زمنية معينة، لذلك يحتاج إلى إعطاء الأولوية في التنزيلات. ومعدل التغييرالمرتفع يعني أن بعض الصفحات قد يكون تم تحديثه أو حتى حذفها.
و عدد العناوين القابلة للزحف والتي تتولد من جانب البرمجيات الخادمة للمواقع على الشبكة جعلت من الصعب تجنب استرجاع محتويات مكرره أثناء الزحف على شبكة الإنترنت. يوجد تركيبات لانهائية من العناوين القائمة على أساس بروتوكول نقل النص الفائق، ولكن في الحقيقة لا يوجد سوى مجموعة صغيرة منها تعيد محتوى فريد. على سبيل المثال، قد يقدم عارض مبسط الصور على الإنترنت ثلاثة خيارات للمستخدمين، على النحو المحدد من خلال معلمات بروتوكول نقل النص الفائق في العنوان. إذا كان هناك أربع طرق لفرز الصور، وثلاثة خيارات لحجم الصورة المصغرة، وطرقتين لتنسيق الملفات، بالإضافة إلى خيار لتعطيل المحتوى القادم من المستخدم، فنفس المجموعة من محتوى يمكن الوصول إليها من خلال 48 عناوين مختلفة، كل منها على الموقع. هذا التوافق الرياضي يخلق مشكلة للزواحف، لأنها يجب أن تفرز من خلال تركيبات لا تنتهي من تغييرات طفيفة نسبيا في لغة البرمجة من أجل استرداد محتوى فريد من نوعه. ويجب أن يختار الزاحف بعناية في كل خطوة الصفحات التي تلي في الزيارة.
سلوك زاحف الشبكة
سلوك زاحف الشبكة هو نتيجة لمزيج من السياسات:[3]
- سياسة الاختيار التي تحدد الصفحات التي ينبغى تحميلها.
- سياسة إعادة الزيارة التي تحدد متى يجب التحقق من التغييرات التي طرأت على الصفحات.
- سياسة الادب التي تنص على كيفية تجنب إثقال الموقع والمزار.
- سياسة الموازاة التي تنص كيفية تنسيق الزواحف الموزعة على الشبكة.
سياسة الانتقاء
بالنظر إلى الحجم الحالي للشبكة، حتى محركات البحث الكبرى لا تستطيع سوى تغطية جزء مما متاح للجمهور. وأظهرت دراسة أجريت عام 2005 ان محركات البحث الكبرى لا تفهرس أكثر من 40 ٪ -70 ٪ من الشبكة المتاحة[4]؛ ودراسة سابقة أجراها الدكتور ستيف لورانس وجايلز لي أظهرت أنه لم يوجد محرك البحث قادر على فهرسة أكثر من 16 ٪ من شبكة الإنترنت في عام 1999.[5] بما ان تنزيلات الزاحف دائما مجرد جزء صغير من صفحات الشبكة، فمن المرغوب فيه جدا أن الجزء المحمل يحتوي على معظم الصفحات ذات الاهمية، وليس مجرد عينة عشوائية من الشبكة.
هذا يتطلب مجدول من الثوابت لتحديد أولويات الصفحات على الشبكة. أهمية الصفحة تنبع من جودتها الذاتية، ومدى شعبيتها من حيث الوصلات أو الزيارات، وحتى من عنوانها (وهذا الثابت الأخير هو الحال في محركات البحث العمودى التي تقتصر على المستوى الأعلى من موقع، أو محركات البحث المقصورة على موقع ثابت). وهناك صعوبة اضافية في تصميم سياسة انتقاء جيدة: وهي انها يجب أن تتعامل مع معلومات جزئية، فأثناء الزحف لا تعرف المجموعة الكاملة من صفحات الشبكة مسبقا.
قام تشو وآخرون بأول دراسة حول السياسات المتعلقة بجدولة الزحف. مجموعة بياناتهم كان زحف على 180000 صفحة من موقع stanford.edu، وتم محاكاة الزحف باستراتيجيات مختلفة.[6] كانت جداول الترتيب التي اختبرت هي الاتساع اولا، وعدد الصلات العائدة، وحسابات ترتيب الصفحة الجزئي. كان واحدا من الاستنتاجات ان الزاحف إذا اراد تحميل الصفحات ذات الرتبة العالية في وقت مبكر خلال عملية الزحف فإن سياسة رتبة الصفحة الجزئي هي الأفضل، وتليها استراتيجية الاتساع أولا، ثم عدد الصلات العائدة. ومع ذلك، فإن هذه النتائج هي لموقع واحد فقط.
نفذ ناجورك ووينر عملية زحف فعلي على 328 مليون صفحة مستخدمين سياسة الاتساع أولا.[7] ووجدوا أن الزحف بسياسة الاتساع أولا يلتقط الصفحات ذات رتبة الصفحة العالية في وقت مبكر من الزحف (لكنهم لم يقارنوا هذه الاستراتيجية ضد استراتيجيات أخرى). التفسير الذي قدمه الباحثون لهذه النتيجة هو أن "أهم صفحات يصلها العديد من الروابط من مضيفين متعددين، وسيتم العثور على تلك الروابط في وقت مبكر، بغض النظر عن المضيف أو الصفحة التي ينشاء منها الزحف".
صمم ابيطبول استراتيجية زحف قائمة على خوارزمية تدعى OPIC (حساب أهمية الصفحة على الإنترنت، أو اوبيك).[8] في أوبيك، تعطى كل صفحة مبلغ أولي من "النقدية" التي يتم توزيعها بالتساوي بين الصفحات التي تشير إليها. وذلك مماثل لحساب رتبة الصفحة، ولكنه أسرع ويتم في خطوة واحدة فقط. والزاحف الذي يستعمل اوبيك ينزل أولا الصفحات في حدود الزحف التي لديها كمية أكبر من "النقد". وأجريت التجارب على رسومات بيانية اصطناعية كل منها يحتوى على 100,000 صفحة، ولكنها لم تقارن مع غيرها من الاستراتيجيات أو في الواقع على الإنترنت.
بولدى وآخرون استخدموا محاكاة على مجموعة مصغرة من الشبكة تحتوى على 40 مليون صفحة تحت منطقة.it الخاصة بإيطاليا و 100 مليون صفحة من الزحف ويب باس، واختبروا استراتيجية الاتساع اولا ضد العمق اولا مع تريب عشوائى واستراتيجية لديها كل المعلومات (كلية العلم). واستندت المقارنة على مدى جودة تقييم رتبة الصفحة المحسوبة على أساس زحف جزئي مقاربة رتبة الصفحة الحقيقية. من المستغرب، ان بعض الزيارات التي تراكم رتبة الصفحة بسرعة كبيرة (وأبرزها، الاتساع اولا، وكلية العلم) تقدم تقديرات تقريبية تدريجية سيئة للغاية.[9][10] بايز ييتس وآخرون استخدموا محاكاة على اثنين من المجموعات المصغرة من الشبكة مكونة من 3 ملايين صفحة من اليونان وشيلى، واختبروا عليها استراتيجيات زحف عدة.[11] وأظهروا أن كلا من استراتيجية اوبيك والاستراتيجية التي تستخدم طول قوائم الانتظار على الموقع هما أفضل من استراتيجية الاتساع اولا، وأن استخدام أي زحف سابق أيضا فعال جدا، عندما يكون متوفرا، لتوجيه الزحف الحالي.
دانيشباجوه وآخرون صمموا خوارزمية لاكتشاف بذور جيدة.[12] طريقتهم تزحف على صفحات الشبكة ذات الرتبة العالية من مجتمعات مختلفة بتكرار أقل بالمقارنة مع بدء الزحف من بذور عشوائية. يمكن للمرء استخراج بذور جيدة من رسم بياني لشبكة تم زحفها مسبقا باستخدام هذا الأسلوب الجديد. وباستخدام هذه البذور سيكون الزحف الجديد فعالا جدا.
المصادر
- Kobayashi, M. and Takeda, K. (2000). "Information retrieval on the web". ACM Computing Surveys. ACM Press. 32 (2): 144–173. doi:10.1145/358923.358934. مؤرشف من الأصل في 28 مارس 2020. الوسيط
|CitationClass=تم تجاهله (مساعدة)صيانة CS1: أسماء متعددة: قائمة المؤلفون (link) - Spetka, Scott. "The TkWWW Robot: Beyond Browsing". المركز الوطني لتطبيقات الحوسبة الفائقة. مؤرشف من الأصل في 03 سبتمبر 2004. اطلع عليه بتاريخ 21 نوفمبر 2010. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Castillo, Carlos (2004). Effective Web Crawling (Ph.D. thesis). University of Chile. مؤرشف من الأصل في 11 ديسمبر 2019. اطلع عليه بتاريخ 03 أغسطس 2010. الوسيط
|CitationClass=تم تجاهله (مساعدة); الوسيط|author=و|last=تكرر أكثر من مرة (مساعدة) - Gulli, A. (2005). "The indexable web is more than 11.5 billion pages". Special interest tracks and posters of the 14th international conference on World Wide Web. ACM Press. صفحات 902–903. doi:10.1145/1062745.1062789. مؤرشف من الأصل في 28 مارس 2020. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Lawrence, Steve (1999-07-08). "Accessibility of information on the web". Nature. 400 (6740): 107. doi:10.1038/21987. PMID 10428673. الوسيط
|CitationClass=تم تجاهله (مساعدة);|access-date=بحاجة لـ|url=(مساعدة) - Cho, J.; Garcia-Molina, H.; Page, L. (1998-04). "Seventh International World-Wide Web Conference". Brisbane, Australia. اطلع عليه بتاريخ 23 مارس 2009. الوسيط
|CitationClass=تم تجاهله (مساعدة); Cite journal requires|journal=(مساعدة); تحقق من التاريخ في:|تاريخ=(مساعدة);|contribution=تم تجاهله (مساعدة)صيانة CS1: أسماء متعددة: قائمة المؤلفون (link) - Marc Najork and Janet L. Wiener. Breadth-first crawling yields high-quality pages. In Proceedings of the Tenth Conference on World Wide Web, pages 114–118, Hong Kong, May 2001. Elsevier Science. نسخة محفوظة 24 ديسمبر 2017 على موقع واي باك مشين.
- Abiteboul, Serge (2003). "Adaptive on-line page importance computation". Proceedings of the 12th international conference on World Wide Web. Budapest, Hungary: ACM. صفحات 280–290. doi:10.1145/775152.775192. ISBN 1-58113-680-3. مؤرشف من الأصل في 14 أغسطس 2018. اطلع عليه بتاريخ 22 مارس 2009. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Boldi, Paolo (2004). "UbiCrawler: a scalable fully distributed Web crawler" (PDF). Software: Practice and Experience. 34 (8): 711–726. doi:10.1002/spe.587. مؤرشف من الأصل (PDF) في 21 ديسمبر 2012. اطلع عليه بتاريخ 23 مارس 2009. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Boldi, Paolo (2004). "Do Your Worst to Make the Best: Paradoxical Effects in PageRank Incremental Computations". Algorithms and Models for the Web-Graph. صفحات 168–180. مؤرشف من الأصل (PDF) في 19 أبريل 2010. اطلع عليه بتاريخ 23 مارس 2009. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Baeza-Yates, R., Castillo, C., Marin, M. and Rodriguez, A. (2005). Crawling a Country: Better Strategies than Breadth-First for Web Page Ordering. In Proceedings of the Industrial and Practical Experience track of the 14th conference on World Wide Web, pages 864–872, Chiba, Japan. ACM Press. نسخة محفوظة 8 يوليو 2020 على موقع واي باك مشين.
- Shervin Daneshpajouh, Mojtaba Mohammadi Nasiri, Mohammad Ghodsi, A Fast Community Based Algorithm for Generating Crawler Seeds Set, In proceeding of 4th International Conference on Web Information Systems and Technologies (WEBIST-2008), Funchal, Portugal, May 2008. نسخة محفوظة 04 يوليو 2018 على موقع واي باك مشين.
انظر أيضًا
 بوابة إنترنت
بوابة إنترنت بوابة تقنية المعلومات
بوابة تقنية المعلومات بوابة علم الحاسوب
بوابة علم الحاسوب
