حوسبة متوازية
الحوسبة المتوازية (بالإنجليزية: Parallel computing) هيَ شكل من أشكال الحوسبة التي يجري فيها تنفيذ العديد من العمليات في وقت واحد[1]، والتي تقوم على مبدأ أنه يمكن في كثير من الأحيان تقسيم المشاكل الكبيرة إلى مشاكل أصغر حجمًا ليتم حلها بشكل مُتوازٍ في نفس الوقت.
للحوسبة المُتوازية عدة مستويات مختلفة:
- التوازي على مستوى البت (بالإنجليزية: Bit-level)
- التوازي على مستوى التعليمات.
- التوازي على مستوى البيانات.
- التوازي على مستوى المهام.
استخدم التوازي لسنوات عديدة، وخاصة في الحوسبة عالية الأداء، ولكن الاهتمام به ازداد أكثر في الآونة الأخيرة بسبب العوائق المادية التي تحول دون توسيع حجم العمليات المعالجة.[2] حيث صار استهلاك أجهزة الحاسوب للطاقة (وبالتالي الحرارة الناتجة عن ذلك) مصدرًا للقلق في السنوات الأخيرة،[3] فإن الحوسبة المتوازية أصبحت النموذج المهيمن في هندسة الحواسيب، وخاصة في نماذج المعالجات متعددة الأنوية.[4]
يُمكن أن تُصنّف الحواسيب المتوازية وفقًا لتصنيف المستوى الذي يدعم العتاد فيه عملية الموازاة. فالحواسيب مُتعددة المُعالجات أو متعددة الأنوية تحتوي على عناصر معالجة متعددة داخل جهاز واحد، في حين أن العناقيد (clusters)، والمعالجات المتوازية الهائلة (MPPS)، ومصفوفات الحواسيب تستخدم عدة حواسيب للعمل على نفس المهمة. تُستخدم هندسة الحواسيب المتوازية المتخصصة أيضا في بعض الأحيان في المُعالجات التقليدية لتسريع أداء مهام محددة.
تُعتبر كتابة البرامج الموجهة للحواسيب المتوازية أكثر صعوبة من البرامج ذات المهام التسلسلية، [5] لأن توازي المهام يسمح بظهور أنواع جديدة محتملة من الأخطاء البرمجية، والتي يُعتبر مشكلة حالة تعارض أحد أشهر أمثلتها.
عادة ما تكون الاتصالات والتزامن بين المهام الفرعية المُختلفة إحدى أكبر العقبات أمام الحصول على برامج متوازية عالية الأداء. يخضع مقدار التسريع في برنامج معين نتيجة لعملية موازة لقانون أمدال.
الخلفية

عادة ما تكون البرامج الحاسوبية مكتوبة بطريقة تسلسلية. فلحل مشكلة ما، تُبنى وتطبق خوارزمية على شكل تعليمات متسلسلة. وتُنفذ هذه التعليمات على وحدة المعالجة المركزية لجهاز حاسوب واحد. حيث تنفذ تعليمة واحدة فقط في نفس الوقت، وبعدَ الانتهاء منها تُنفذ التعليمة التالية.[6]
أما الحوسبة المتوازية فتستخدم في وَقت واحد عدة عناصر معالجة لحل مشكلة معينة. وتقسَّم المشكلة إلى أجزاء مستقلة بحيث يمكن لكل عنصر من عناصر المعالجة تنفيذ الجزء الخاص به من الخوارزمية في وقت واحد مع العناصر الأخرى. تتنوع العناصر المعالجة وتشمل موارد مختلفة مثل جهاز حاسوب واحد مع معالجات متعددة أو شبكة من عدة حواسيب أو معدات متخصصة أو أي مزيج مما ذكر.[6]
كان رفعُ سرعة تنفيذ العمليات الهم الرئيسي لتحسين أداء الحواسيب منذ منتصف ثمانيات القرن العشرين وحتى عام 2004. حيث أن مدة تنفيذ برنامج تساوي عدد التعليمات مضروبًا في متوسط الوقت اللازم لتنفيذ تعليمة واحد. الحفاظ على كل شيء ثابتًا، وزيادة تردد الساعة الداخلية يخفض من متوسط الوقت المستغرق لتنفيذ تعليمة. وبالتالي يُقلل وقت التنفيذ لجميع البرامج ذات العمليات المحدودة.[7]
يحسب استهلاك الشرائح للطاقة من خلال المعادلة P = C × V2 × F،حيث ترمز P إلى الطاقة، وترمز C إلى عدد المكثفات المستعملة أثناء عمل دورة كاملة (تتناسب مع عدد الترانزستورات التي تتغير مدخلاتها)، وترمز V إلى الجهد، أما F فترمز إلى تردد المعالج (دورة في الثانية).[8] وتزيد زيادة التردد من كمية الطاقة المستهلكة. أجبَرَت زيادة استهلاك المعالجات للطاقة في النهاية شركة إنتل في مايو 2004على إلغاء إنتاج معالجاتها تيجاس وجهوك، والتي تعتبر عمومًا نهاية سياسة رفع التردد كنموذج شائع لمعمارية الحواسيب.[9]
على الرغم من قضايا استهلاك الطاقة إضافة للتنبؤات المتكررة عن نهايته، فإن قانون مور ظل صحيحًا. فقد نصَّ قانون مور (الناتج عن ملاحظة تجريبية) على أن كثافة الترانزستورات في المعالجات الدقيقة تتضاعف كل 18 إلى 24 شهرًا.[10] وبنهاية سياسة زيادة التردد، فقد أمكن استخدام هذه الترانزستورات الإضافية (التي لم تعد تستخدم لرفع التردد) لإضافة أجهزة أخرى من أجل إجراء حوسبة متوازية.
قانون أمدال، وقانون غوستافسون
 مقالات مفصلة: قانون أمدال
مقالات مفصلة: قانون أمدال- قانون غوستافسون
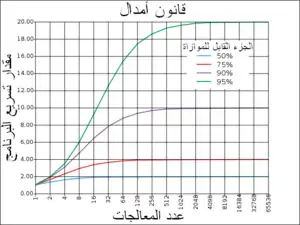
بنظرة مثالية، فإن مقدار التسريع الناتج عن عملية الموازاة سيكون خطيا، أي بمضاعفة عدد عناصر المعالجة ينبغي خفض وقت التشغيل إلى النصف، وبمضاعفته مرة أخرى ينبغي خفض وقت التنفيذ إلى النصف مرة أخرى. ومع ذلك، عدد قليل جدا من الخوارزميات المتوازية تحقق مقدار التسريع المثالي. فمعظمها لديها مقدار تسريع قريب من مقدار التسريع المثالي عند استخدام أعداد قليلة من عناصر المعالجة، والذي يتحول إلى قيمة ثابتة عند استخدام عدد أكبر من عناصر المعالجة.
إن مقدار التسريع المحتمل لخوارزمية في بيئة حوسبة متوازية تحسب باستخدام قانون أمدال، والذي وضعه جين أمدال في ستينيات القرن العشرين.[11] والذي ينص على أن أي جزء صغير من البرنامج لا يمكن موازاته سوف يحد من مقدار التسريع الإجمالي المتاح بعملية الموازاة. أي مشكلة رياضية أو هندسية كبيرة عادة ما تتألف من عدة أجزاء قابلة للموازاة وأجزاء أخرى غير قابلة للموازاة (أجزاء متسلسلة). وتعطى هذه العلاقة من المعادلة :

حيث S هو مقدار تسريع البرنامج (بصفته عاملا من عوامل وقت تنفيذ الخوارزمية التسلسلية الأصلية)، وP هو الجزء القابل للموازاة. إذا كان الجزء غير القابل للموازاة من برنامج يستهلك 10% من وقت التنفيذ، فإنه من غير الممكن أن نحصل على مقدار تسريع أكثر من عشرة أضعاف، بغض النظر عن عدد المعالجات التي تم إضافتها. وهذا يضع حدا أعلى للفائدة من إضافة وحدات تنفيذ متوازية أكثر. "عندما لا يمكن تقسيم مهمة بسبب قيود تمنع عملية التقسيم، فإن تطبيق مزيد من الجهد ليس له تأثير على الجدول الزمني. فحمل الطفل يأخذ تسعة أشهر ولا علاقة لذلك بعدد النسوة".[12]
قانون غوستافسون هو قانون آخر في هندسة الحاسبات، ويرتبط ارتباطا وثيقا بقانون أمدال. ويمكن صياغته على النحو التالي :


حيث P هو عدد المعالجات، S هو مقدار التسريع وα هو الجزء غير القابل للموازاة من هذه العملية.[13] يفترض قانون أمدال أن للمشكلة حجما ثابتا وأن حجم المقطع المتسلسل مستقل عن عدد المعالجات، في حين أن القانون غوستافسون لم يقم بهذه الافتراضات.
الاعتمادية
فهم الاعتمادية على البيانات أمر أساسي في تنفيذ الخوارزميات المتوازية. لا يمكن تشغيل برنامج بسرعة أكبر من أطول سلسلة من العمليات الحسابية المعتمدة على بعضها (المعروف باسم المسار الحرج)، لأن الحسابات التي تعتمد على حسابات سابقة في السلسلة يجب أن تنفذ بالترتيب. ومع ذلك، فإن معظم الخوارزميات لا تتكون من مجرد سلسلة طويلة من العمليات الحسابية المعتمدة على بعضها ؛ عادة ما تكون هناك فرص لتنفيذ بالتوازي عمليات حسابية مستقلة.
ليكن Pi و Pj جزأين من برنامج. شروط برنشتاين [14] تصف متى يمكن تنفيذ جزأين مستقلين بشكل متواز. لكل Pi، افرض ان Ii يمثل كافة المتغيرات المدخلة وOi المتغيرات المخرجة، وكذلك الأمر مع Pj. فإن P i وPj مستقلان إذا حققا الشروط التالية:



انتهاك الشرط الأول يسبب اعتمادية التتابع، بالاعتماد على نتائج الشرط الأول تنتج الجملة الثانية نتائجها. الشرط الثاني يمثل مضاد للتبعية، عندما (Pj) يحاول التصرف في متغير يحتاجه (Pi). الشرط الثالث والأخير يمثل التبعية في المخرجات : عندما تكتب الجملتين على نفس المخرج، يجب أن تأتي النتيجة النهائية من آخر جملة تنفذ منطقيا.[15]
بالنظر إلى المهام التالية، والتي تمثل عدة أنواع من الاعتمادية:
1: function Dep(a, b)
2: c = a·b
3: d = 2·c
4: end function
لا يمكن تنفيذ عملية السطر 3 قبل (أو حتى في موازاة مع) عملية السطر 2، لأن عملية السطر 3 تستخدم نتيجة عملية من السطر 2. وذلك لا عدم تحقق الشرط 1، وبهذا تكون هناك اعتمادية التتابع.
1: NoDep function (a, b)
2: c = a·b
3: d = 2·b
4: e = a+b
5: end function
في هذا المثال، لا توجد اعتمادية بين التعليمات، وبالتالي يمكن تنفذهم جميعا بالتوازي.
شروط برنشتاين لا تسمح باشتراك الذاكرة بين العمليات المختلفة. لذلك، فإن فرض بعض الترتيب بين عمليات الوصول للذاكرة ضروري، مثلا نظام إشارات (semaphores)، أو الحواجز أو بعض طرق التزامن الأخرى.
حالة السباق واستبعاد التشارك والتزامن والتباطؤ في التوازي
في برنامج مواز غالبا ما تسمى المهام الفرعية خيوطا (بالإنجليزية: Threads). بعض هندسة الحواسيب المتوازية تستخدم نسخ صغيرة وخفيفة من الخيوط المعروفة باسم الألياف، بينما تستخدم هندسات أخرى نسخ أكبر تسمى بالعمليات. ومع ذلك فإن "الخيوط" مقبولة عموما كمصطلح عام عن المهام الفرعية.
غالبا ما تحتاج الخيوط إلى تحديث بعض المتغيرات مشتركة بينها. يمكن ترتيب التعليمات المشتركة بين البرنامجين بأي ترتيب. على سبيل المثال، البرنامج التالي :
| الخيط أ | الخيط ب |
| 1أ: قراءة المتغير س | 1ب : قراءة المتغير س |
| 2أ: إضافة 1 إلى قيمة س | 2ب: إضافة 1 إلى قيمة س |
| 3أ طباعة س | 3ب طباعة س |
إذا تم تنفيذ التعليمة 1ب بين 1أ و3أ، أو إذا تم تنفيذ التعليمات 1أ بين 1ب و3ب، سيقوم البرنامج بإنتاج بيانات غير صحيحة. وهذا هو المعروف باسم حالة السباق (بالإنجليزية: Race condition). يجب على المبرمج استخدام قفل لضمان استبعاد التشارك. القفل هو بناء في لغة البرمجة يسمح لخيط واحد بالسيطرة على متغير ومنع الخيوط الأخرى من القراءة أو الكتابة بها، حتى تحرير المتغير من القفل. الخيط الذي قام بعملية القفل يمكنه تنفيذ الجزء الحرج (القسم من البرنامج الذي يتطلب وصول حصري إلى المتغير)، وبعدها يقوم بتحرير البيانات بعدما ينهي هذا الجزء. لذلك، لضمان تنفيذ البرنامج السابق بشكل صحيح، يمكن إعادة صياغته باستخدام الأقفال:
| الخيط أ | الخيط ب |
| 1أ: ضع قفلا على المتغير س | 1ب: ضع قفلا على المتغير س |
| 2أ: قراءة المتغير س | 2ب: قراءة المتغير س |
| 3أ: إضافة 1 إلى قيمة س | 3ب: إضافة 1 إلى قيمة س |
| 4أ: طباعة س | 4ب: طباعة س |
| 5أ : حرر متغير س | 5B : حرر متغير س |
سوف يقوم خيط واحد بقفل المتغير س، في حين أن الخيوط الأخرى ستكون مستبعدة، وغير قادرة على المضي قدما إلى أن يتم تحرير المتغير س مرة أخرى. وهكذا يتم ضمان تنفيذ البرنامج بشكل صحيح. تستعمل الأقفال عند الضرورة لتنفيذ البرنامج بشكل صحيح، لكن العملية يمكن أن تبطئ هذا البرنامج بشكل كبير.
قفل عدة متغيرات باستخدام أقفال غير موحدة يدخل البرنامج في طريق مسدود. الأقفال الموحدة تقفل كل المتغيرات مرة واحدة. وإذا لم يتمكن من قفلهم جميعا، فإنه لن يقفل اي واحد منهم. إذا احتاج خيطان لحجز نفس المتغيرين باستعمال قفل غير موحد، من الممكن أن يحجز أحد الخيوط أحد المتغيرات بينما يحجز الخيط الثاني المتغير الآخر. في مثل هذه الحالة، لا يمكن لأي خيط منهما إنهاء عمله ويصلان لطريق مسدود.
كثير من البرامج المتوازية تتطلب تزامنا بين مهامها الفرعية، وهذا يتطلب استخدام حاجز. والذي عادة ما ينفذ باستخدام قفل برمجي. فئة من الخوارزميات، تعرف بإقفال-تحرير وانتظار-تحرير، تتجنب استخدام الأقفال والحواجز تماما. ولكن هذا النهج صعب التنفيذ غالبا ويتطلب تصميم تركيبة بيانات بشكل صحيح.
لا تؤدي كل عمليات الموازاة إلى التسريع. عموما، كلما قسمت المهام إلى خيوط أكثر فأكثر، فإن تلك الخيوط ستستهلك جزء زائد من الوقت في التواصل مع بعضهم البعض. في نهاية المطاف، فإن الوقت الزائد من عملية الاتصال يهيمن على الوقت الذي يستغرقه حل المشكلة، وكذلك عملية الموازاة (أي تقسيم عبء العمل على خيوط أكثر) تزيد بدلا من أن تقلل من مقدار الوقت المطلوب لانتهاء. يعرف هذا بتباطؤ التوازي (بالإنجليزية: Parallel slowdown).
توازي الحبيبات الناعمة والحبيبات الخشنة والمربك
غالبا ما تصنف التطبيقات وفقا لمدى حاجة المهام الفرعية للمزامنة أو التواصل مع بعضها البعض. يظهر التطبيق توازي الحبيبات الناعمة (بالإنجليزية: Fine-grained parallelism) إذا كانت المهام الفرعية تتواصل عدة مرات في الثانية الواحدة، أو توازي الحبيبات الخشنة (بالإنجليزية: Coarse-grained parallelism) إذا لم تتواصل عدة مرات في الثانية الواحدة، ويصنف بالتوزاي المربك (بالإنجليزية: Embarrassing parallelism) إذا كانت نادرا ما تضطر للتواصل أو لا يوجد تواصل إطلاقا. تعتبر التطبيقات من صنف التوازي المربك أسهل للموازاة.
نماذج تناسق

يجب أن يكون للغات البرمجة المتوازية ولأجهزة الحاسوب المتوازية نموذج تناسق (المعروف أيضا باسم نموذج الذاكرة). نموذج التناسق (بالإنجليزية: Consistency model) يحدد القواعد لكيفية حدوث العمليات في ذاكرة الحاسوب، وكيفية إنتاج النتائج.
واحد من نماذج التناسق هو نموذج "ليسلي لامبورت" للتناسق المتسلسل. التناسق المتسلسل هو خاصية للبرنامج المتوازي الذي ينتج عن تنفيذه بشكل متواز نفس النتائج إذا نفذ بشكل تسلسلي. بشكل أدق، يكون البرنامج متطابق تسلسليا إذا "... نتائج أي تنفيذ هي نفسها إذا ما نفذت كل العمليات على كل المعالجات بترتيب متسلسل ما، والعمليات في كل معالج تظهر في هذا التسلسل بالترتيب المحدد من قبل البرنامج".[16]
ذاكرة معاملات البرنامج هي نوع شائع من نماذج التناسق. تستعمل ذاكرة معاملات البرنامج مفهوما، استعير من نظريات قواعد البيانات وتطبيقها، هو مفهوم المعاملات الموحدة (بالإنجليزية: Atomic transactions) في عملية الوصول إلى الذاكرة.
رياضيا، يمكن تمثيل هذه النماذج بعدة طرق. شبكة بيتري، الذي تم عرضها في أطروحة الدكتوراه لآدم كارل بيتري سنة 1962، كانت محاولة مبكرة لتدوين قواعد نماذج التناسق. بعدها تم بناء نظرية تدفق البيانات، وتم إنشاء هندسة تدفق البيانات كتطبيق عملي لفكرة نظرية تدفق البيانات. بدأت في أواخر سبعينات القرن العشرين، حيث تم تطوير جبر العمليات مثل حسابات أنظمة الاتصالات وعمليات الاتصال التسلسلية للسماح بالتفكير بشكل جبري حول نظم مكونة من عناصر متفاعلة. إضافات جديدة إلى عائلة جبر العمليات، مثل π-calculus الذي أضاف إمكانية التفكير في طبولوجيا ديناميكية. المنطق مثل Lamport's TLA+ والنماذج الرياضية مثل التعقب ومخططات الأحداث الفاعلة، طورت أيضا لوصف سلوك النظم المتنافسة.
تصنيف فلين
- مقالة مفصلة: تصنيف فلين
قام مايكل ج. فلين بإنجاز واحدة من أوائل نظم التصنيف للحاسبات والبرنامج المتوازية (والمتسلسلة)، والتي تعرف الآن باسم تصنيف فلين (بالإنجليزية: Flynn's taxonomy). صنف فلين برامج وأجهزة الحاسوب من خلال إذا كانت تعمل باستخدام مجموعة واحدة أو عدة مجموعات من تعليمات، مهما يكن عدد المجموعات من البيانات التي تستخدمها هذه التعليمات مجموعة واحدة أو أكثر.
| تصنيف فلين |
|---|
| تدفق بيانات واحد |
| تدفقات بيانات متعددة |
تصنيف تعليمة واحدة على معلومة واحدة (بالإنجليزية: Single-instruction-single-data SISD) ما يعادل برنامج متسلسل تماما. بينما تصنيف تعليمة واحدة على بيانات متعددة (بالإنجليزية: Single-instruction-multiple-data SIMD) يماثل القيام بالعملية نفسها مرارا وتكرارا على مجموعة كبيرة من البيانات. وهذا هو الشائع في تطبيقات معالجة الإشارات. تعليمات متعددة على معلومة واحدة (بالإنجليزية: Multiple-instruction-single-data MISD) هو تصنيف نادر الاستخدام. في حين أن هندسة الحاسبات انقسمت في التعامل مع هذا التصنيف، فإن عدد قليل من التطبيقات تتناسب مع هذا التصنيف تم تجسيدها. برامج تعليمات متعددة على بيانات متعددة (بالإنجليزية: Multiple-instruction-multiple-data MIMD) هي إلى حد بعيد، النوع الأكثر شيوعا بين البرامج المتوازية.
وفقا لديفيد باترسون وجون هينيسي فإن "بعض الآلات الهجينة من هذه الفئات، وبالطبع أن هذه النماذج الكلاسيكية قد عمر طويلا لأنها بسيطة وسهلة الفهم، وتعطي تقريبا أوليا جيد. وهو أيضا المخطط الأكثر استعمال وعلى نطاق واسع، ربما بسبب سهولة فهمه".[17]
أنواع التوازي
التوازي على مستوى البت
- مقالة مفصلة: توازي على مستوى البت
منذ بدايات تكنولوجيا دارات التكامل الفائق (بالإنجليزية: Very-large-scale integration VLSI) في تصنيع رقائق الحاسوب في سبعينات القرن العشرين وحتى حوالي عام 1986، كانت تتم عملية التسريع في هندسة الحاسبات من خلال مضاعفة حجم كلمة الحاسوب، والتي بدورها تزيد كمية المعلومات التي يمكن للمعالج أن يعالجها في كل دورة.[18] زيادة حجم الكلمة يقلل من عدد التعليمات التي يجب على المعالج تنفيذها لأداء عملية على متغيرات حجمها أكبر من طول الكلمة. على سبيل المثال، عند جمع رقمين صحيحين مكونين من 16 بت على معالج 8 بت، فإن المعالج يقوم بجمع أول 8 بت من كل رقم باستخدام تعليمة الجمع، ثم يجمع ثاني 8 بت مع الإعارة من العملية السابقة، وبالتالي فإن معالج 8 بت يحتاج لتعليمتين لإكمال عملية واحدة، بينما معالج 16 بت معالج سيكون قادر على إكمال العملية بتعليمة واحدة.
تاريخيا، تم استبدال المعالجات 4-بت بمعالجات 8 بت ثم 16 بت، ثم 32 بت. وبشكل عام فقد وصل هذا الاتجاه إلى نهايته مع إدخال معالجات 32 بت، التي سائدة في الحاسبات العامة لعقدين من الزمن. ولكن ليس إلى غاية وقت قريب (2003-2004)، حيث ظهرت هندسة x86-64، والتي تحوي على معالجات 64 بت وشاع استخدامها.
التوازي على مستوى التعليمات

(IF = Instruction Fetch (إحضار التعليمة)،
ID = Instruction Decode (ترجم التعليمة)،
EX = Execute (تنفيذ)،
MEM = Memory access (وصول للذاكرة)،
WB = Register write back (سجل الكتابة مرة أخرى))
برنامج حاسوبي في جوهره وهو دفق من التعليمات التي ينفذها المعالج. يمكن إعادة ترتيب هذه التعليمات ودمجها في مجموعات يتم تنفيذها بالتوازي دون تغيير نتيجة هذا البرنامج. وهذا ما يسمى بالموازاة على مستوى التعليمات. تطور فكرة الموازاة على مستوى التعليمات هيمنة على هندسة الحاسبات من منتصف ثمانينات وحتى منتصف تسعينات القرن العشرين.[19]
المعالجات الحديثة لديها خطوط أنابيب متعددة المراحل. كل مرحلة في خط الأنابيب توافق عملا مختلفا يقوم به المعالج على التعليمات في هذه المرحلة؛ المعالج الذي يحوي ن مرحلة في خط أنابيب يمكن أن ينجز حتى ن تعليمة مختلفة في مراحل مختلفة. وتعد المعالجات من نوع RISC مثال على المعالجات التي تعمل بنظام خطوط الأنابيب، وفي هذا النوع من المعالجات خمس مراحل: جلب التعليمة، وفك الشفرة، وتنفيذها، والوصول إلى الذاكرة، وكتابة النتائج. المعالج بنتيوم 4 له 35 مراحل في خط الأنابيب.[20]
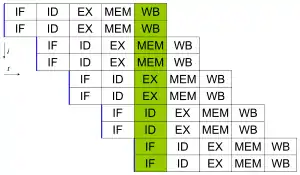
بالإضافة إلى الموازاة على مستوى التعليمات باستخدام خط الأنابيب، يمكن لبعض المعالجات معالجة أكثر من تعليمة في نفس الوقت. تعرف بالمعالجات سوبرسكيلر. تجمع التعليمات معا إذا لم يكن هناك أي تبعية في البيانات فيما بينها. تعد خوارزمية "سكوربوردنج" وخوارزمية "توماسلو" (التي تشبه سكوربوردنج ولكن تقوم بإعادة تسمية السجلات) من أكثر الأساليب شيوعا لتنفيذ التعليمات بدون ترتيب في تنفيذ الموازاة على مستوى التعليمة.
موازاة البيانات
موازاة البيانات هي عملية الموازاة المتأصلة في جمل التكرار في البرنامج، التي تركز على توزيع هذه البيانات عبر عقد الحوسبة المختلفة بحيث تتم معالجتها بشكل متواز. "غالبا ما تؤدي موازاة التكرار بصورة مماثلة (ليست بالضرورة مطابقة) إلى تسلسل العمليات أو المهام التي تؤدى على عناصر بيانات ذات هياكل كبيرة." [21] العديد من التطبيقات العلمية والهندسية تستعمل توازي البيانات.
الاعتمادية في حلقات التكرار هي اعتمادية حلقة تكرار على ناتج واحدة أو أكثر من حلقات التكرار السابقة لها. وهذه الاعتمادية في حلقات التكرار تمنع القيام بعمل توزيع لعمليات التكرار. على سبيل المثال، بالنظر إلى الكود التالي الذي يحسب بعض أعداد فيبوناتشي الأولى :
1 : PREV1 = 0
2: PREV2 = 1
4: do:
5: CUR = PREV1 + PREV2
6 : PREV1 = PREV2
7 : PREV2 = CUR
8: while (CUR < 10)
لا يمكن توزيع هذا التكرار لان CUR يعتمد عليه PREV2 وPREV1، والتي يتم حسابها في كل حلقة تكرار. ولأن التكرار يعتمد في نتيجة على المرحلة السابقة، فلا يمكن أن يتم تنفيذها في نفس الوقت. وبتعاظم حجم مشكلة، يتعاظم مقدار توازي البيانات المتاحة عادة.[22]
توازي المهام
- مقالة مفصلة: توازي على مستوى المهام
موازاة المهام هي صفة البرامج المتوازية التي تحوي "حسابات مختلفة تماما يمكن أن تنفذ في نفس المجموعة أو في مجموعة مختلفة من البيانات".[21] وهذا يتناقض مع موازاة البيانات، حيث يتم تنفيذ نفس العملية الحسابية على نفس المجموعة أو مجموعات مختلفة من البيانات. توازي المهام لا تتناسب عادة مع حجم المشكلة.[22]
العتاد
الذاكرة والاتصالات
تكون الذاكرة الرئيسية في أجهزة الحواسيب المتوازية إما ذاكرة مشتركة (تشترك جميع عناصر المعالجة في مساحة تخزينية واحدة) أو ذاكرة موزعة (التي يكون فيها لكل عنصر من عناصر التجهيز مساحة تخزينية محلية خاصة به).[23] ومصطلح الذاكرة الموزعة يعني أن الذاكرة موزعة منطقيا، ولكن غالبا ما يعني أيضا أنها موزعة ماديا. الذاكرة المشتركة الموزعة والذاكرة الافتراضية تجمعان بين النهجين، حيث أن كل عنصر معالجة يملك ذاكرة محلية خاصة به وسبيلا للوصول إلى ذاكرة على معالجات غير المحلية. الوصول للذاكرة المحلية عادة ما يكون أسرع من الوصول إلى الذاكرة غير المحلية.
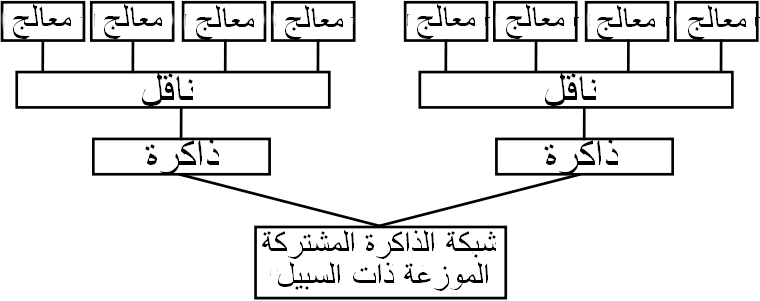
هندسة الحواسيب التي يكون فيها كل عنصر من الذاكرة الرئيسية متوفرا بنفس المدة والتدفق تعرف بالذاكرة موحدة الوصول (بالإنجليزية: Uniform Memory Access : UMA). لا يمكن أن يتحقق هذا إلا من خلال نظام ذاكرة مشتركة حيث لا وجود لتوزيع مادي للذاكرة. النظم التي ليس لديها هذه الخاصية تعرف بنظم الذاكرة غير موحدة الوصول (بالإنجليزية: Non-Uniform Memory Access - NUMA). نظم الذاكرة الموزعة هي ذاكرة غير موحدة الوصول.
تستفيد نظم الحاسوب من مخزن صغير وسريع بقرب من المعالج لتخزين مؤقت لنسخ من قيم الذاكرة. أما أنظمة الحواسيب المتوازية فتواجه صعوبات مع هذه المخازن التي قد تخزن القيمة نفسها في أكثر من مكان واحد، مع إمكانية تنفيذ غير صحيح للبرنامج. أجهزة الحاسوب هذه تتطلب نظام تخزين متناسق، والذي يتتبع القيم المخزنة مؤقتا ويعمل على تطهير إستراتيجيا لها، وبالتالي ضمان تنفيذ صحيح للبرنامج. قنوات التطفل هي واحدة من أكثر الطرق شيوعا لتتبع القيم التي يتم الوصول إليها (وبالتالي ينبغي تطهيرها). تصميم نظام تخزين متناسق عالي الكفاءة وكبير هي مشكلة صعبة للغاية في مجال هندسة الحواسيب. ونتيجة لذلك، فإن هندسة الحواسيب بذاكرة مشتركة لا تتناسب جيدا مع أنظمة الذاكرة الموزعة.[23]
يمكن تنفيذ الاتصالات بين الذاكرة والمعالجات وفيما بين المعالجات باستعمال أجهزة بطرق متعددة، بما في ذلك عبر ذاكرة مشتركة أو عارضة تبديل (بالإنجليزية: Crossbar switch) أو ناقل مشترك أو شبكة ربط لعدد لا يحصى من طبولوجيات بما في ذلك طبولوجيات الطوق والنجمة والشجرة، هايبر مكعب (بالإنجليزية: Hypercube)، هايبر مكعب ضخم (بالإنجليزية: Fat hypercube)؛ أي هايبر مكعب بأكثر من معالج في العقدة الواحدة، أو شبكة من ن-بعد.
تحتاج الحواسيب المتوازية (المبنية على أساس شبكات الربط) إلى نوع من التوجيه لتمكينها من تمرير الرسائل بين العقد التي لا علاقة مباشرة بينها. من المرجح أن تكون الوسيلة المستخدمة للاتصال بين المعالجات هي التسلسل الهرمي في الأجهزة الكبيرة متعددة المعالجات.
فئات الحواسيب المتوازية
يمكن تصنيف الحواسيب المتوازية وفقا للمستوى الذي يدعم فيه الجهاز عملية التوازي. هذا التصنيف هو على نطاق واسع مماثل للمسافة بين العقد الحوسبة. كلاهما لا يستبعد بعضها البعض، على سبيل المثال، عناقيد الحواسيب متعددة المعالجات المتماثلة هي شائعة نسبيا.
حوسبة متعددات الأنوية
- مقالة مفصلة: معالج متعدد الأنوية
المعالج متعدد الأنوية (بالإنجليزية: Multicore) هو معالج يتضمن عدة وحدات تنفيذ ("النوى") على نفس الشريحة. هذه المعالجات تختلف عن المعالجات "سوبرسكيلر" (بالإنجليزية: Superscalar)، والتي يمكنها تمرير تعليمات متعددة لكل دورة من سيل واحد من التعليمات (خيط أو thread)؛ على النقيض من ذلك، يمكن للمعالجات متعددة الأنوية تمرير تعليمات متعددة لكل دورة من سيول تعليمات متعددة. كل نواة في المعالج متعدد الأنوية يمكنها أن تكون سوبرسكيلر. ففي كل دورة، ويمكن لكل نواة تمرير تعليمات متعددة من سيل واحد.
معالجة متزامنة لعدة خيوط (بالإنجليزية: Multithreading) في وقت واحد (وتقنية خيوط المعالجة الفائقة لإنتل هي الأكثر شهرة) وشكل مبكر من شبه تعدد الأنوية (بالإنجليزية: Pseudo-multicoreism). معالج قادر على معالجة متزامنة لعدة خيوط لديه وحدة تنفيذ واحدة ("نواة")، ولكن عندما تكون وحدة التنفيذ خاملة (مثل حالة جلب بيانيات)، فإنها تستخدم في تنفيذ الخيط الثاني. معالج آي بي إم Cell، المصمم للاستخدام في سوني بلاي ستيشن 3، هو معالج بارز آخر متعدد الأنوية.
المعالجة المتعددة المتماثلة
- مقالة مفصلة: المعالجات المتعددة المتماثلة
المعالجات المتعددة المتماثلة (بالإنجليزية: Symmetric multiprocessor - SMP) هو نظام حاسوبي ذو معالجات متعددة متطابقة تتشارك ذاكرة وقناة اتصال (أو ناقل).[24] الزحام في الناقل يمنع هندسة النواقل من التزايد. ونتيجة لذلك، فعموما لا تضم المعالجات المتعددة المتماثلة أكثر من 32 معالج.[25] "نظرا لصغر حجم المعالجات والانخفاض الكبير في متطلبات لسعة التدفق التي تحققها المخابئ الكبيرة، مثل هذه المعالجات المتماثلة فعالة للغاية من حيث التكلفة، شريطة أن تكون كمية كافية من سعة التدفق للذاكرة متوفرة." [24]
الحوسبة الموزعة
- مقالة مفصلة: حوسبة موزعة
الحاسوب الموزع (المعروف أيضا بالمعالجات موزعة الذاكرة) هو نظام حاسوبي موزع الذاكرة ترتبط فيه العناصر المعالجة من خلال شبكة. الحواسيب الموزعة قابلة للتزايد.
الحوسبة العنقودية
- مقالة مفصلة: حوسبة عنقودية

العنقود (بالإنجليزية: Cluster)، هو مجموعة من أجهزة الحواسيب المتقاربة التي تعمل معا بشكل وثيق، حتى أنه في بعض النواحي تعتبر بمثابة جهاز حاسوب واحد.[26] تتكون العناقيد من مجموعة من آلات مستقلة متعددة ومتصلة بواسطة شبكة حاسوبية. لا يشترط أن تكون آلات العنقود الواحد متماثلة، ولكن عملية موازنة الحمل فيما بينها تصبح أكثر صعوبة إذا لم تكن كذلك. النوع المتعارف عليه هو عنقود بياولف (بالإنجليزية: Beowulf cluster)، وتمثل مجموعة من أجهزة الحاسوب متعددة ومتطابقة مرتبطة بشبكة محلية تعمل بحزمة برتوكولات حزمة بروتوكولات الإنترنت بوصلات إيثرنت.[27] قام بتطوير تقنية بياولف كل من توماس ستيرلينغ ودونالد بيكر. وتشكل الحواسيب العنقودية الغالبية العظمى من حواسيب قائمة توب 500 لأقوى أنظمة الحواسيب في العالم.[28]
المعالجة عالية التوازي
- مقالة مفصلة: حاسوب متوازي هائل
المعالج عال التوازي (بالإنجليزية: Massively parallel processor-MPP) هو جهاز حاسوب واحد مع معالجات شبكية كثيرة. هذه الأجهزة لها العديد من خصائص العناقيد، ولكنها تملك شبكات خاصة (في حين أن العناقيد تستخدم عتاد للشبكات). وتميل إلى أن تكون أكبر من العناقيد، وعادة "أكثر بكثير" من 100 معالج.[29] في المعالج عال التوازي، "كل وحدة معالجة مركزية تحتوي على ذاكرة خاصة بها، ونسخة من نظام التشغيل والبرمجية. كل فرع يتصل مع الآخرين عبر وصلات عالية السرعة.[30]

بلو جين/L المعالج عالي التوازي هو خامس أسرع حاسوب عملاق في العالم وفقا لتصنيف توب 500 ليونيو 2009.
الحوسبة الشبكية
- مقالة مفصلة: حوسبة شبكية
الحوسبة الشبكية (بالإنجليزية: Grid computing) هي الشكل الأكثر انتشارا للحوسبة المتوازية. إنه يستخدم اتصال أجهزة الحاسوب عبر الإنترنت للعمل على مشكلة معينة. وبسبب انخفاض سرعة تدفق البيانات والبطء التباعد العالي للغاية على شبكة الإنترنت، فإن الحوسبة الشبكية تتعامل عادة فقط مع مشاكل التوازي الحرج. تم إنشاء عدة برمجيات للحوسبة الشبكية، أشهرها:[31] ستي@هوم وفولدنغ@هوم.
معظم برمجيات الحوسبة الشبكية تستخدم برمجيات وسيطة (بالإنجليزية: Middleware)، وهي برمجيات تعمل بين نظام التشغيل والبرمجيات الأخرى لإدارة موارد الشبكة وتوحد الواجهة البرمجية. أكثر البرمجيات الوسيطة للحوسبة الشبكية شيوعا هي بنية باركلي التحتية المفتوحة للحوسبة شبكية (بالإنجليزية: Berkeley Open Infrastructure for Network Computing-BOINC). في كثير من الأحيان، تقوم برامج الحوسبة الشبكية بإتمام "دورات إضافية"، وأداء عمليات حسابية عندما يكون جهاز الحاسوب خاملا.
الحواسيب المتوازية المتخصصة
توجد في الحوسبة المتوازية أجهزة متوازية متخصصة لم تلفت إليها الاهتمام بعد. في حين أنه من غير تعيين الميادين، فإنها تميل إلى تطبيق على عدد قليل فقط من فئات المشاكل التوازي.
الحوسبة قابلة لإعادة التشكيل مع FPGA
الحوسبة القابلة لإعادة التشكيل هو استخدام مصفوفات البوابات المنطقية القابلة للبرمجة في الميدان (بالإنجليزية: Field-Programmable Gate Array-FPGA) كمعالج مشارك للأغراض العامة للحاسوب. FPGA في جوهره شريحة حاسوب يمكنها إعادة ربط نفسها لمهمة معينة.
يمكن برمجة FPGA بلغة وصف الأجهزة VHDL أو "فيريلوج". لكن البرمجة بهذه اللغات قد تكون مملة، لهذا تم إنشاء عدة لغات من فئة C to HDL كمحاولة لمحاكاة صياغة ودلالات لغة البرمجة سي، التي اعتاد عليها معظم المطورين. الأكثر شهرة بين لغات C to HDL هي Mitrion-C و Impulse C و DIME-C و Handel-C. كما يوجد مجموعات فرعية معينة من SystemC مبنية على أساس سي++ يمكن أن تستخدم أيضا لهذا الغرض.
قرار أي إم دي بفتح تكنولوجية هيبرترانسبورت للمطورين العاديين فتح المجال لتكنولوجيا لإعادة تشكيل الحوسبة عالية الأداء.[32] وفقا إلى مايكل ر. دامور، الرئيس التنفيذي للعمليات في شركة DRC للحوسبة: "في الأول عندما كنا نسير نحو أي إم دي، وصفونا بسارقي المأخذ. والآن يسموننا بشركائهم".[32]
الحوسبة للأغراض العامة على وحدات المعالجة الرسومية
- مقالة مفصلة: وحدة معالجة الرسوميات

الحوسبة للأغراض العامة على وحدة معالجة الرسوميات (بالإنجليزية: General-Purpose Computing on Graphics Processing Units-GPGPU) هو اتجاه حديث نسبيا في مجال الأبحاث في هندسة الحواسيب. وحدات معالجة الرسومات هي معالجات مساعدة شهدت تطورا مكثفا لمعالجة الرسومات على الحاسوب.[33] معالجة الرسومات بالحاسوب هو أحد الميادين الذي تهيمن عليه العمليات المتوازية لمعالجة البيانات وبصفة خاصة عمليات الجبر الخطي على المصفوفات.
في البدايات، استخدمت برمجيات GPGPU واجهات المكتبات الرسومية العادية لتنفيذ البرامج. ومؤخرا ظهرت لغات برمجة ومنصات جديدة بنيت لاستعمال المعالجات الرسومية لأمور عامة غير الغرض الأصلي لها. خاصة بعد أن أصدر كل من إنفيديا وأي إم دي بيئات للبرمجة هي كودا (CUDA) وسي.تي.إم (CTM) على التوالي. إضافة إلى لغات أخرى لبرمجة المعالجات الرسومية مثل BrookGPU و PeakStream و RapidMind. وقد أصدرت إنفيديا أيضا منتجات محددة لإجراء العمليات الحسابية في سلسلة تسلا (Tesla series).
التطبيقات الخاصة بالدوائر المتكاملة
انقسم نهج عدة تطبيقات من نوع أسيك (ASIC) في التعامل مع البرامج المتوازية.[34][35][36]
لأن أسيك (وحسب التعريف) هو خاص بتطبيق معين، فإنه يمكن أن تطويره ليكون الأمثل لهذا التطبيق. وكنتيجة لتطبيق معين، فإن أسيك يميل للتفوق في الحوسبة لأغراض عامة. تصنع أسيك بتقنية X-ray lithography. وهذه العملية تتطلب قناعا (قد يكون مكلفا للغاية). تكلفة قناع واحد يمكن أن تتجاوز مليون دولار أمريكي.[37] (كلما كانت الترانزستورات أصغر للرقاقة المطلوبة، فإن تكلفة القناع تكون أكبر). وفي الوقت نفسه، يزيد على مر الزمن أداء الحوسبة لأغراض عامة (مثلما يصفها قانون مور) تميل للقضاء على هذه المكاسب في جيل أو جيلين للرقاقة.[32] التكلفة الأولية العالية جعلت أسيك غير مجدية بالنسبة لمعظم تطبيقات الحوسبة المتوازية. ومع ذلك، فقد تم بناء بعضها. ومن الأمثلة على ذلك جهاز RIKEN MDGRAPE-3 الذي يستخدم أسيك مخصصة لمحاكاة ديناميات الجزيئية.
المعالجات المتجهية

المعالج المتجهي (بالإنجليزية: Vector processor) هو وحدة معالجة مركزية أو حاسوب يمكنه تنفيذ نفس التعليمات على مجموعات كبيرة من البيانات. "للمعالجات المتجهية مستوى عمليات رفيع للعمل على المصفوفات الخطية من الأرقام أو المتجهات. من الأمثلة على العمليات على المتجهات A = B × C، حيث A و B و C متجهات من 64 عنصر لكل منها وأعداد حقيقية 64بت" [38] ولهذا صلة وثيقة هي بتصنيف في فلين تعليمة واحدة على بيانات كثيرة.[38]
ما بين سبعينيات وثمانينيات القرن العشرين، أصبحت شركة كراي مشهورة بحواسيبها متجهية المعالجة. ومع ذلك، فإن المعالجات المتجهية مثلها مثل وحدات المعالجة المركزية وأنظمة الحواسيب الكاملة اختفت عموما. مجموعات تعليمات المعالجات الحديثة تشمل بعض التعليمات لمعالجة المتجهات مثلما هو الشأن مع AltiVec و SSE.
البرمجيات
لغات البرمجة المتوازية
من أجل برمجة الحواسيب المتوازية، تم إنشاء لغات البرمجة والمكتبات وواجهات برمجة التطبيقات ونماذج للبرمجة المتوازية. وعموما تنقسم لغات البرمجة إلى فئات استنادا إلى ما تقدمه من الافتراضات حول هندسة الذاكرة والذاكرة المشتركة والذاكرة الموزعة، أو الذاكرة المشتركة الموزعة. لغات البرمجة التي تتعامل بذاكرة مشتركة تتواصل عن طريق التلاعب بالمتغيرات في الذاكرة المشتركة. مع الذاكرة الموزعة يستخدم تمرير الرسائل. خيوط بوسيكس (بالإنجليزية: POSIX Threads) وأوبن أم بي من أكثر واجهات برمجة التطبيقات بذاكرة مشتركة استخداما. في حين أن إم بي آي (بالإنجليزية: Message Passing Interface-MPI) هو نظام تمرير الرسائل الأكثر استخداما على نطاق واسع.[39] أحد المفاهيم المستخدمة في كتابة البرامج المتوازية هو مفهوم المستقبل، حيث يعِد جزء واحد من البرنامج بتسليم المسند المطلوب إلى جزء آخر من برنامج في وقت ما في المستقبل.
الموازاة التلقائية
استحداث موازاة تلقائيا لبرنامج متسلسل يقوم بها برنامج ترجمة (مترجم-Compiler) هي قمة الحوسبة المتوازية. ورغم مرور عقود من عمل الباحثين على المترجمات، إلا أن الحصول على موازاة تلقائيا سجلت نجاح محدود فقط.[40]
المذهب الأساسي في لغات البرمجة المتوازية يبقى إما توازي صريح أو (في أحسن الأحوال) ضمني جزئيا، حيث يعطي المبرمج التوجيهات للمترجم بالموازاة. يوجد عدد قليل من لغات البرمجة المتوازية ضمنيا، مثل "السيزال" و"برلال هاسكل"، و(من أجل FPGA) يستعمل Mitrion-C.
برمجيات التدقيق والفحص
الحاسوب الأكبر حجما والأكثر تعقيدا هو الأكثر تعرضا للخطأ والفترة الزمنية المتوسطة بين الإخفاقات فيه هي الأقصر. برمجيات التدقيق والفحص تقنية بموجبها يقوم نظام الحاسوب بأخذ صورة عن حالة برنامج (تسجيل عن كل الموارد الحالية المحجوزة والحالات المتغيرة)، وهي أقرب إلى تفريغ. هذه المعلومات يمكن استخدامها لاستعادة البرنامج في حال فشل الحاسوب. التدقيق والفحص يعني أن البرنامج يعاد تشغيله من آخر نقطة تدقيق فقط وليس من البداية. لتطبيق قد يعمل للأشهر فإن الأمر بالغ الأهمية. يمكن استخدام برمجيات التدقيق والفحص لتسهيل عملية الهجرة.
أنواع الخوارزميات
بما أن الحواسيب المتوازية صارت أكبر وأسرع، فإنه أصبح من الممكن حل المشاكل التي كانت سابقا تأخذ وقتا طويلا. تستخدم الحوسبة المتوازية في مجالات واسعة، من تكنولوجيا المعلومات الحيوي إلى الاقتصاد (الرياضيات المالية). الأنواع الشائعة من المشاكل التي وجدت في تطبيقات الحوسبة المتوازية هي :[41]
- الجبر الخطي الكثيف.
- الجبر الخطي المتفرق.
- الطرق الطيفية (مثل كولي-توكي تحويل فورييه السريع).
- مشاكل ن-هيئة (مثل محاكاة بارنز-هت).
- مشاكل الشبكة البنائية (بالإنجليزية: Structured grid problems)، مثل أساليب بولتزمان المشبك.
- مشاكل الشبكة غير المنظمة (مثل الموجودة في تحليل العناصر المحدودة أو المنتهية).
- محاكاة مونتي كارلو.
- المنطق التوافقي (مثل تقنيات القوة الغاشمة في التشفير).
- الرسم البياني الاجتيازي (مثل خوارزميات الترتيب).
- البرمجة الديناميكية.
- أساليب التفريع والربط (بالإنجليزية: Branch and bound methods).
- النماذج الرسومية (مثل الكشف عن نموذج ماركوف المخفي وبناء شبكة بايزية).
- محاكاة آلة محدودة الأوضاع.
تاريخ

أصول التوازي الصحيح (عمليات مختلفة على بيانات مختلفة-MIMD) يعود إلى لويجي فيديريكو، كونت Menabrea وما قدمه في "وصف مقتضب للمحرك التحليلي الذي اخترعه تشارلز باباج.[42][43] أدخلت شركة آي بي إم حاسوب 704 في عام 1954، من خلال المشروع الذي كان جين أمدال أحد المهندسين الرئيسيين فيه. ليصبح أول حاسوب تجاري متاح لاستخدام مجموعة كاملة من الأوامر الحسابية بطريقة تلقائية.[44]
في أبريل 1958، ناقش س. جيل (فيرانتي) البرمجة المتوازية، والحاجة إلى التفرع والانتظار.[45] في عام 1958، ناقش الباحثان جون كوك ودانيال سلوتنيك (العاملين في شركة آي بي إم) استخدام التوازي في العمليات الحسابية العددية للمرة الأولى.[46] أدرجت شركة بوروز (بالإنجليزية: Burroughs Corporation) معالج D825 في سنة 1962، وهو معالج حواسيب رباعي يمكنه الوصول إلى 16 وحدات ذاكرة من خلال العارضة التبديل [47] في عام 1967، نشر سلوتنيك وأمدال نقاشا حول جدوى المعالجة المتوازية في مؤتمر جمعيات الاتحاد الأمريكي للمعالجة المعلومات.[46] ومن خلال هذه المناقشة صيغ قانون أمدال لتحديد الحد الأقصى للسرعة المكتسبة من عملية الموازاة.
في عام 1969، قدمت الشركة الأمريكية هونيويل نظامها الأول مالتيكس، وهو نظام متعدد المعالجات المتماثلة قادر على تشغيل ما يصل إلى ثمانية معالجات بالتوازي.[46] مشروع C.mmp في سبعينيات القرن العشرين التابع لجامعة كارنيجي ميلون هو أول متعدد المعالجات بمعالجات قليلة".[43] "إن أول ناقل لوصل عدة معالجات مع مخابئ التطفل (بالإنجليزية: Snooping caches) هو Synapse N+1 كان ذلك في عام 1984." [43]
ويمكن إرجاع الحواسيب المتوازية (تعليمة واحدة على بيانات مختلفة) إلى سبعينيات القرن العشرين. كان الدافع وراء هذا النوع من الحواسيب في وقت مبكر هو توزيع تأخير بوابة التحكم لوحدة المعالجة على تعليمات متعددة.[48] في عام 1964، اقترح "سلوتنيك" بناء حاسوب متوازية على نطاق واسع لمختبر لورانس ليفرمور الوطني.[46] موّل التصميم، الذي كان من أوائل الحواسيب المتوازية،[46] من قبل سلاح الجو الأمريكي، وسمي "ILLIAC 4". المفتاح في تصميمه كان التوازي العالي نوعا ما، مع ما يصل إلى 256 معالج، والتي تسمح للآلة بالعمل على مجموعات كبيرة من البيانات في ما عرف لاحقا بالمعالجة المتجهية. ومع ذلك، 4 ILLIAC سمي "أكثر الحواسيب العملاقة المجهولة"، وذلك لأن المشروع لم يكن سوى أحد الأربعة اكتمالا، ولكن استغرق 11 سنوات، وتكلفة فاقت أربع مرات تقريبا عن التقديرات الأصلية.[49] وأخيرا عندما صار على استعداد للتشغيل الحقيقي في التطبيق الأول في عام 1976، كانت قد تفوقت عليه حواسيب عملاقة تجارية مثل كراي 1.
دماغ بيولوجي كحاسوب عال التوازي
في أوائل سبعينيات القرن العشرين، بدأ كل من مارفن مينسكي وسيمور بابيرت في معهد ماساتشوستس لعلوم الحاسوب والذكاء الاصطناعي [الإنجليزية] في تطوير ما أصبح يعرف بنظرية «مجتمع العقل» الذي تنظر إلى الدماغ البيولوجي كحاسوب عال التوازي. في عام 1986، نشر مينسكي كتاب "مجتمع العقل"، يقول فيه بأن "العقل يتكون من عدد من الوكلاء (agents) الصغار، كل وكيل هو عقل في حد ذاته".[50] وتحاول النظرية تفسير بأن ما نسميه ذكاءا يمكن أن يكون نتيجة لتفاعل أجزاء غير الذكية. ويقول مينسكي بأن أكبر مصدر للأفكار حول النظرية جاء من عمله في محاولة لإنشاء آلة تستخدم ذراع الروبوت، وكاميرا فيديو، وجهاز حاسوب لبناء بكتل الأطفال.[51]
ظهرت نماذج مماثلة (ترى أيضا في الدماغ البيولوجي حاسوبا عال التوازي، أي أن الدماغ يتكون من كوكبة من الوكلاء المستقلين أو شبه المستقلين) وصفها كل من :
- Thomas R. Blakeslee,[52]
- مايكل غازانيغا,[53][54]
- Robert E. Ornstein،[55]
- Ernest Hilgard،[56][57]
- ميتشيو كاكو،[58]
- جورج غوردجييف،[59]
- نموذج العنقود العصبي (بالإنجليزية: Neurocluster Brain Model).[60]
انظر أيضًا
مراجع
- Almasi, G.S. and A. Gottlieb (1989). Highly Parallel Computing. Benjamin-Cummings publishers, Redwood City, CA. نسخة محفوظة 11 فبراير 2020 على موقع واي باك مشين.
- S.V. Adve et al. (November 2008). "Parallel Computing Research at Illinois: The UPCRC Agenda" (PDF). Parallel@Illinois, University of Illinois at Urbana-Champaign. "The main techniques for these performance benefits – increased clock frequency and smarter but increasingly complex architectures – are now hitting the so-called power wall. The computer industry has accepted that future performance increases must largely come from increasing the number of processors (or cores) on a die, rather than making a single core go faster." نسخة محفوظة 05 2يناير3 على موقع واي باك مشين.
- Asanovic et al. Old [conventional wisdom]: Power is free, but transistors are expensive. New conventional wisdom is that power is expensive, but transistors are "free".
- Asanovic, Krste et al. (December 18, 2006). "The Landscape of Parallel Computing Research: A View from Berkeley" (PDF). University of California, Berkeley. Technical Report No. UCB/EECS-2006-183. "Old [conventional wisdom]: Increasing clock frequency is the primary method of improving processor performance. New [conventional wisdom]: Increasing parallelism is the primary method of improving processor performance ... Even representatives from Intel, a company generally associated with the 'higher clock-speed is better' position, warned that traditional approaches to maximizing performance through maximizing clock speed have been pushed to their limit." نسخة محفوظة 06 يوليو 2018 على موقع واي باك مشين.
- Patterson, David A. and John L. Hennessy (1998). Computer Organization and Design, Second Edition, Morgan Kaufmann Publishers, p. 715. ISBN 1-55860-428-6.
- Barney, Blaise. "Introduction to Parallel Computing". Lawrence Livermore National Laboratory. مؤرشف من الأصل في 28 سبتمبر 2006. اطلع عليه بتاريخ 09 نوفمبر 2007. الوسيط
|CitationClass=تم تجاهله (مساعدة) - John L. Hennessy and David A. Patterson (2002). Computer Architecture: A Quantitative Approach. 3rd edition, Morgan Kaufmann, p. 43. ISBN 1-55860-724-2.
- Rabaey, J. M. (1996). Digital Integrated Circuits. Prentice Hall, p. 235. ISBN 0-13-178609-1.
- Flynn, Laurie J. "Intel Halts Development of 2 New Microprocessors". The New York Times, May 8, 2004. Retrieved on April 22, 2008. نسخة محفوظة 03 أبريل 2015 على موقع واي باك مشين.
- Moore, Gordon E. (1965). "Cramming more components onto integrated circuits" (PDF). Electronics Magazine. صفحة 4. مؤرشف من الأصل (PDF) في 14 يناير 2013. اطلع عليه بتاريخ 11 نوفمبر 2006. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Amdahl, G. (April 1967) "The validity of the single processor approach to achieving large-scale computing capabilities". In Proceedings of AFIPS Spring Joint Computer Conference, Atlantic City, N.J., AFIPS Press, pp. 483–85.
- Brooks, Frederick P. Jr. The Mythical Man-Month: Essays on Software Engineering. Chapter 2 – The Mythical Man Month. ISBN 0-201-83595-9
- Reevaluating Amdahl's Law (1988). Communications of the ACM 31(5), pp. 532–33. نسخة محفوظة 06 2يناير2 على موقع واي باك مشين.
- Bernstein, A. J. (October 1966). "Program Analysis for Parallel Processing,' IEEE Trans. on Electronic Computers". EC-15, pp. 757–62.
- Roosta, Seyed H. (2000). "Parallel processing and parallel algorithms: theory and computation". Springer, p. 114. ISBN 0-387-98716-9.
- Lamport, Leslie (September 1979). "How to Make a Multiprocessor Computer That Correctly Executes Multiprocess Programs", IEEE Transactions on Computers, C-28,9, pp. 690–91.
- Patterson and Hennessy, p. 748.
- Culler, David E.; Jaswinder Pal Singh and Anoop Gupta (1999). Parallel Computer Architecture - A Hardware/Software Approach. Morgan Kaufmann Publishers, p. 15. ISBN 1-55860-343-3.
- Culler et al. p. 15.
- Yale Patt (April 2004). "The Microprocessor Ten Years From Now: What Are The Challenges, How Do We Meet Them? (wmv). Distinguished Lecturer talk at جامعة كارنيغي ميلون. Retrieved on November 7, 2007. نسخة محفوظة 12 يونيو 2010 على موقع واي باك مشين.
- Culler et al. p. 124.
- Culler et al. p. 125.
- Patterson and Hennessy, p. 713.
- Hennessy and Patterson, p. 549.
- Patterson and Hennessy, p. 714.
- What is clustering? Webopedia computer dictionary. Retrieved on November 7, 2007. نسخة محفوظة 23 سبتمبر 2017 على موقع واي باك مشين.
- Beowulf definition. PC Magazine. Retrieved on November 7, 2007. نسخة محفوظة 10 أكتوبر 2012 على موقع واي باك مشين.
- Architecture share for 06/2007. توب 500 Supercomputing Sites. Clusters make up 74.60% of the machines on the list. Retrieved on November 7, 2007. [وصلة مكسورة] نسخة محفوظة 13 يونيو 2011 على موقع واي باك مشين.
- Hennessy and Patterson, p. 537.
- MPP Definition. PC Magazine. Retrieved on November 7, 2007. نسخة محفوظة 11 مايو 2013 على موقع واي باك مشين.
- Kirkpatrick, Scott (January 31, 2003). "Computer Science: Rough Times Ahead". Science, Vol. 299. No. 5607, pp. 668 - 669. DOI: 10.1126/science.1081623
- D'Amour, Michael R., Chief Operating Officer, DRC Computer Corporation. "Standard Reconfigurable Computing". Invited speaker at the University of Delaware, February 28, 2007.
- Boggan, Sha'Kia and Daniel M. Pressel (August 2007). GPUs: An Emerging Platform for General-Purpose Computation (PDF). ARL-SR-154, U.S. Army Research Lab. Retrieved on November 7, 2007. نسخة محفوظة 25 ديسمبر 2016 على موقع واي باك مشين. [وصلة مكسورة]
- Maslennikov, Oleg (2002). "Systematic Generation of Executing Programs for Processor Elements in Parallel ASIC or FPGA-Based Systems and Their Transformation into VHDL-Descriptions of Processor Element Control Units". Lecture Notes in Computer Science, 2328/2002: p. 272. نسخة محفوظة 11 فبراير 2020 على موقع واي باك مشين. [وصلة مكسورة]
- Shimokawa, Y.; Y. Fuwa and N. Aramaki (18–21 November 1991). A parallel ASIC VLSI neurocomputer for a large number of neurons and billion connections per second speed. IEEE International Joint Conference on Neural Networks. 3: pp. 2162–67. نسخة محفوظة 06 فبراير 2015 على موقع واي باك مشين.
- Acken, K.P.; M.J. Irwin, R.M. Owens (July 1998). "A Parallel ASIC Architecture for Efficient Fractal Image Coding". The Journal of VLSI Signal Processing, 19(2):97–113(17) نسخة محفوظة 21 أكتوبر 2012 على موقع واي باك مشين. [وصلة مكسورة]
- Kahng, Andrew B. (June 21, 2004) "Scoping the Problem of DFM in the Semiconductor Industry." University of California, San Diego. "Future design for manufacturing (DFM) technology must reduce design [non-recoverable expenditure] cost and directly address manufacturing [non-recoverable expenditures] – the cost of a mask set and probe card – which is well over $1 million at the 90 nm technology node and creates a significant damper on semiconductor-based innovation." نسخة محفوظة 03 مارس 2012 على موقع واي باك مشين. [وصلة مكسورة]
- Patterson and Hennessy, p. 751.
- The Sidney Fernbach Award given to MPI inventor Bill Gropp refers to MPI as the "the dominant HPC communications interface" نسخة محفوظة 09 مايو 2018 على موقع واي باك مشين.
- Shen, John Paul and Mikko H. Lipasti (2005). Modern Processor Design: Fundamentals of Superscalar Processors. McGraw-Hill Professional. p. 561. ISBN 0-07-057064-7. "However, the holy grail of such research - automated parallelization of serial programs - has yet to materialize. While automated parallelization of certain classes of algorithms has been demonstrated, such success has largely been limited to scientific and numeric applications with predictable flow control (e.g., nested loop structures with statically determined iteration counts) and statically analyzable memory access patterns. (e.g., walks over large multidimensional arrays of float-point data)."
- Asanovic, Krste, et al. (December 18, 2006). The Landscape of Parallel Computing Research: A View from Berkeley (PDF). University of California, Berkeley. Technical Report No. UCB/EECS-2006-183. See table on pages 17–19. نسخة محفوظة 06 يوليو 2018 على موقع واي باك مشين.
- Menabrea, L. F. (1842). Sketch of the Analytic Engine Invented by Charles Babbage. Bibliothèque Universelle de Genève. Retrieved on November 7, 2007. نسخة محفوظة 29 يوليو 2018 على موقع واي باك مشين.
- Patterson and Hennessy, p. 753.
- da Cruz, Frank (2003). "Columbia University Computing History: The IBM 704". Columbia University. مؤرشف من الأصل في 14 مايو 2011. اطلع عليه بتاريخ 08 يناير 2008. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Parallel Programming, S. Gill, The Computer Journal Vol. 1 #1, pp2-10, British Computer Society, April 1958.
- Wilson, Gregory V (1994). "The History of the Development of Parallel Computing". Virginia Tech/Norfolk State University, Interactive Learning with a Digital Library in Computer Science. مؤرشف من الأصل في 28 ديسمبر 2018. اطلع عليه بتاريخ 08 يناير 2008. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Anthes, Gry (November 19, 2001). "The Power of Parallelism". Computerworld. مؤرشف من الأصل في 06 يناير 2009. اطلع عليه بتاريخ 08 يناير 2008. الوسيط
|CitationClass=تم تجاهله (مساعدة); تحقق من التاريخ في:|تاريخ أرشيف=(مساعدة) - Patterson and Hennessy, p. 749.
- Patterson and Hennessy, pp. 749–50: "Although successful in pushing several technologies useful in later projects, the ILLIAC IV failed as a computer. Costs escalated from the $8 million estimated in 1966 to $31 million by 1972, despite the construction of only a quarter of the planned machine ... It was perhaps the most infamous of supercomputers. The project started in 1965 and ran its first real application in 1976."
- Minsky, Marvin (1986). The Society of Mind. New York: Simon & Schuster. صفحات 17. الوسيط
|CitationClass=تم تجاهله (مساعدة)صيانة CS1: التاريخ والسنة (link) - Minsky, Marvin (1986). The Society of Mind. New York: Simon & Schuster. صفحات 29. ISBN 0-671-60740-5. مؤرشف من الأصل في 9 يناير 2020. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Blakeslee, Thomas (1996). Beyond the Conscious Mind. Unlocking the Secrets of the Self. صفحات 6–7. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Gazzaniga, Michael; LeDoux, Joseph (1978). The Integrated Mind. صفحات 132–161. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Gazzaniga, Michael (1985). The Social Brain. Discovering the Networks of the Mind. صفحات 77–79. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Ornstein, Robert (1992). Evolution of Consciousness: The Origins of the Way We Think. صفحة 2. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Hilgard, Ernest (1977). Divided consciousness: multiple controls in human thought and action. New York: Wiley. ISBN 978-0-471-39602-4. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Hilgard, Ernest (1986). Divided consciousness: multiple controls in human thought and action (expanded edition). New York: Wiley. ISBN 0-471-80572-6. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Kaku, Michio (2014). Future of the Mind. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Ouspenskii, Pyotr (1992). "Chapter 3". In Search of the Miraculous. Fragments of an Unknown Teaching. صفحات 72–83. الوسيط
|CitationClass=تم تجاهله (مساعدة) - "Official Neurocluster Brain Model site". مؤرشف من الأصل في 31 ديسمبر 2017. اطلع عليه بتاريخ 22 يوليو 2017. الوسيط
|CitationClass=تم تجاهله (مساعدة)
كتب
- (بالإنجليزية) Patterson, David A. and John L. Hennessy, Computer Organization and Design, Morgan Kaufmann Publishers, 1998 (Second Edition) ISBN 1-55860-428-6.
- (بالإنجليزية) Culler, David E.; Jaswinder Pal Singh and Anoop Gupta (1999)., Parallel Computer Architecture - A Hardware/Software Approach, Morgan Kaufmann Publishers ISBN 1-55860-343-3.
وصلات خارجية
- (بالعربية) مدخل إلى الحوسبة المتوازية
- (بالعربية) كتاب محاضرات الحاسبات المتوازية والبرمجة المتوازية
- (بالعربية) المعالجة المتوازية - مقال من الموسوعة العربية
- (بالإنجليزية) حوسبة متوازية على مشروع الدليل المفتوح
- (بالإنجليزية) مختبر لورانس ليفرمور الوطني: مدخل إلى الحوسبة المتوازية
- (بالإنجليزية) تصميم وبناء البرامج المتوازية، تأليف إيان فوستر
- (بالإنجليزية) أرشيف الحوسبة المتوازية على شبكة الإنترنت
- (بالإنجليزية) مواضيع حول البرمجة المتوازية في موقع IEEE للحوسبة المنشورة (المضمون غير متوفر بتاريخ 14 مايو 2011)
- (بالإنجليزية) كتاب مجاني حول أعمال الحوسبة المتوازية
- (بالإنجليزية) كتاب مجاني حول حدود الحوسبة الفائقة. يغطي عدّة مواضيع بما فيها الخوارزميات والتطبيقات الصناعية
- (بالإنجليزية) المركز العالمي لبحوث الحوسبة المتوازية
- (بالإنجليزية) حلقة دراسية حول الحوسبة المتوازية في جامعة كولومبيا (بالتعاون مع مشروع J.T واطسون X10) (المضمون غير متوفر بتاريخ 14 مايو 2011)
 بوابة علم الحاسوب
بوابة علم الحاسوب بوابة حوسبة علمية
بوابة حوسبة علمية بوابة تقنية المعلومات
بوابة تقنية المعلومات