اختبار قابلية الاستخدام
اختبارات الاستخدام أو (اختبار قابلية الاستخدام) هي تقنية وخطة مدروسة مستخدمة في التصاميم التفاعلية التي تتمحور حول المستخدم وذلك بغرض تقييم منتج أو مشروع عن طريق اختباره وتجربته على المستخدمين. يمكن اعتبار ذلك ممارسة سهلة الاستخدام لا يمكن الاستغناء عنها، لأنها تقدم مدخلات مباشرة حول كيفية استخدام المستخدمين الحقيقيين للنظام الذي تم إنشائه حديثاً.[1] يتناقض هذا الاختبار مع الطرق المستخدمه لفحص قابلية الاستخدام، حيث يستخدم الخبراء طرقًا مختلفة لتقييم واجهة المستخدم دون إشراك المستخدمين.
يرتكز اختبار قابلية الاستخدام على قياس قدرة المنتج وقياس ما إذا كان هذا المنتج قادر على تحقيق الغرض المقصود منه والأهداف المتطلبة والمأمولة منه أيضاً. أمثلة على المنتجات التي تستفيد بشكل شائع من اختبار قابلية الاستخدام هي الأغذية والمنتجات الاستهلاكية ومواقع الويب أو تطبيقات الويب وواجهات الحاسب والمستندات والأجهزة بشكل عام. اختبار قابلية الاستخدام يقيس قابلية الاستخدام بشكل خاص وسهولة الاستخدام بشكل عام، حيث يركز أيضاً على كائنات معينة في مراحل تطوير وتصميم المنتج ومجموعة من كائنات وعناصر الاستخدام الاخرى، في حين تحاول دراسات التفاعل بين الإنسان والحاسوب صياغة مبادئ عالمية.
ما ليس من خصائص الاختبار
ببساطة جمع الآراء حول كائن معين أو مستند داخل نطاق المشروع أو المنتج هو من مهام أبحاث السوق أو البحث النوعي بدلاً من أن يكون داخل خصائص اختبار قابلية الاستخدام. يتضمن اختبار قابلية الاستخدام عادةً مراقبة منهجية معينة في ظل ظروف محكومة لتحديد مدى قدرة الناس على استخدام المنتج.[2] ومع ذلك، غالباً ما يتم استخدام كل من الاختبار النوعي وقابلية الاستخدام في الجمع، لفهم دوافع / تصورات المستخدمين بشكل أفضل، بالإضافة إلى تصرفاتهم.
بدلاً من إظهار مسودة تقريبية للمستخدمين وسؤالهم "هل تفهم هذا؟" ، يتضمن اختبار قابلية الاستخدام مشاهدة الأشخاص الذين يحاولون استخدام شيء ما للغرض المقصود منه. على سبيل المثال، عند اختبار إرشادات تجميع لعبة ما، يجب إعطاء وإرفاق مواضيع الاختبار والإرشادات وعلبة من الأجزاء، وبدلاً من طلب التعليق على الأجزاء والمواد، يُطلب منهم وضع وتجميع اللعبة معاً. تؤثر صياغة التعليمات وجودة التوضيح وتصميم اللعبة على عملية التجميع.
أساليب
يتضمن إعداد اختبار قابلية الاستخدام إنشاء سيناريو أو موقف واقعي بعناية، حيث يقوم الشخص بقائمة من المهام باستخدام المنتج الجاري اختباره أثناء مراقبة ومشاهدة وتدوين الملاحظات ( التحقق الديناميكي ). كما يتم استخدام العديد من أدوات الاختبار الأخرى مثل الإرشادات النصية والنماذج الأولية للورق واستبيانات ما قبل وما بعد الاختبار لجمع الملاحظات حول المنتج الجاري اختباره ( التحقق الثابت ). على سبيل المثال، لاختبار وظيفة المرفقات في برنامج البريد الإلكتروني ، يصف سيناريو الحالة التي يحتاج فيها الشخص إلى إرسال مرفق البريد الإلكتروني، ويطلب منه القيام بهذه المهمة. الهدف من ذلك هو ملاحظة كيفية عمل الأشخاص بطريقة واقعية، بحيث يمكن للمطورين رؤية مناطق المشاكل وما يعجبهم الأشخاص وما لا يعجبهم. تشمل التقنيات المستخدمة بشكل شائع لجمع البيانات أثناء اختبار قابلية الاستخدام بروتوكول التفكير بصوت عال والتعلم المشترك في الاكتشاف وتتبع العين .
اختبار الردهة
يُعد اختبار الردهة طريقة سريعة ورخيصة لاختبار قابلية الاستخدام، حيث يُطلب من الأشخاص الذين يتم اختيارهم عشوائياً - مثل الأشخاص الذين يمرون في الردهة - محاولة استخدام المنتج أو الخدمة. يمكن أن يساعد ذلك المصممين على تحديد "المختصرات" ، وهي مشكلات خطيرة للغاية بحيث لا يمكن للمستخدمين التقدم في المراحل المبكرة من التصميم الجديد. يمكن استخدام أي شخص باستثناء مصممي المشروع والمهندسين (يميلون إلى العمل كمراجعين خبراء لأنهم قريبون جداً من المشروع).
اختبار قابلية الاستخدام عن بعد
في سيناريو حيث يوجد المقيمين لاختبار قابلية الاستخدام والمطورين والمستخدمين المحتملين في بلدان ومناطق زمنية مختلفة، فإن إجراء تقييم قابلية الاستخدام التقليدي للمختبرات يخلق تحديات من حيث التكلفة ومنظورات النقل والإمداد. أدت هذه المخاوف إلى إجراء أبحاث حول تقييم قابلية الاستخدام عن بُعد، مع فصل المستخدم والمقيمين عن المكان والزمان. يمكن أن يكون الاختبار عن بُعد، الذي يسهل التقييمات التي تتم في سياق المهام والتقنيات الأخرى للمستخدم، إما متزامناً أو غير متزامن. الأولى تتضمن اتصالاً فردياً في الوقت الفعلي بين المُقيِّم والمستخدم، في حين أن الأخير ينطوي على المُقيِّم والمستخدم الذي يعمل بشكل منفصل.[3] تتوفر العديد من الأدوات لتلبية احتياجات هذين الأسلوبين.
تتضمن منهجيات اختبار قابلية الاستخدام المتزامن مؤتمرات الفيديو أو استخدام أدوات مشاركة التطبيقات عن بعد مثل WebEx. WebEx و GoToMeeting هما أكثر التقنيات استخداماً لإجراء اختبار قابلية الاستخدام عن بُعد المتزامن.[4] ومع ذلك، قد يفتقر الاختبار المتزامن عن بُعد إلى السرعة والإحساس "بوجود" المرغوب فيه لدعم عملية الاختبار التعاوني. علاوة على ذلك، فإن إدارة الديناميات بين الأفراد عبر الحواجز الثقافية واللغوية قد تتطلب مقاربات حساسة للثقافات المعنية. تشمل العيوب الأخرى تقليل التحكم في بيئة الاختبار والانحرافات والانقطاعات التي يعاني منها المشاركون في بيئتهم الأصلية.[5] من الأساليب الحديثة المطورة لإجراء اختبار قابلية الاستخدام عن بُعد المتزامن استخدام العوالم الافتراضية.[6]
تتضمن المنهجيات غير المتزامنة التجميع التلقائي لتدفقات نقرات المستخدم وسجلات المستخدم للحوادث الخطيرة التي تحدث أثناء التفاعل مع التطبيق والتعليقات الشخصية على الواجهة من قبل المستخدمين.[7] غرار الدراسة داخل المختبر، فإن اختبار قابلية الاستخدام غير المتزامن عن بُعد يعتمد على المهام وتتيح المنصة للباحثين التقاط النقرات وأوقات المهام. وبالتالي، بالنسبة للعديد من الشركات الكبيرة، يسمح هذا للباحثين بفهم نوايا الزوار بشكل أفضل عند زيارة موقع ويب أو موقع جوال. بالإضافة إلى ذلك، يوفر هذا النمط من اختبار المستخدم أيضاً فرصة لتعليقات القطاعات حسب النوع الديموغرافي والسلوكي. يتم إجراء الاختبارات في بيئة المستخدم الخاصة (بدلاً من المعامل) مما يساعد على محاكاة اختبار السيناريو الواقعي بشكل أكبر. يوفر هذا النهج أيضاً وسيلة لالتماس التعليقات بسهولة من المستخدمين في المناطق النائية بسرعة وبأعباء تنظيمية أقل. في السنوات الأخيرة، أصبح إجراء اختبار قابلية الاستخدام بشكل غير متزامن سائداً ويسمح للمختبرين بتقديم ملاحظات في أوقات فراغهم وبشكل مريح في منازلهم.
مراجعة الخبراء
مراجعة الخبراء هي طريقة عامة أخرى لاختبار قابلية الاستخدام. كما يوحي الاسم، تعتمد هذه الطريقة على استقدام خبراء من ذوي الخبرة في هذا المجال (ربما من الشركات المتخصصة في اختبار قابلية الاستخدام) لتقييم قابلية استخدام المنتج.
التقييم الاسترشادي أو تدقيق قابلية الاستخدام هو تقييم لواجهة المستخدم من قبل واحد أو أكثر من خبراء العوامل البشرية. يقيس المُقيِّمون قابلية الاستخدام والكفاءة والفعالية للواجهة استناداً إلى مبادئ قابلية الاستخدام، مثل معايير قابلية الاستخدام العشرة التي حددها في الأصل "جاكوب نيلسن" في عام 1994.[8]
تشمل معايير قابلية الاستخدام الخاصة بشركة Nielsen ، والتي استمرت في التطور استجابة لأبحاث المستخدم والأجهزة الجديدة، ما يلي:
- وضوح حالة النظام
- التطابق بين النظام والعالم الحقيقي
- تحكم المستخدم والحرية
- الاتساق والمعايير
- منع الخطأ
- الاعتراف بدلا من التذكير
- المرونة وكفاءة الاستخدام
- التصميم الجمالي والحد الأدنى
- مساعدة المستخدمين على التعرف على الأخطاء وتشخيصها والتعافي منها
- المساعدة والوثائق
مراجعة الخبير الآلي
على غرار مراجعات الخبراء، توفر مراجعات الخبراء الآلية اختبار قابلية الاستخدام، ولكن من خلال استخدام برامج معينة لقواعد التصميم والاستدلال الجيد. على الرغم من أن المراجعة التلقائية قد لا توفر الكثير من التفاصيل والبصيرة مثل المراجعات من الأشخاص، إلا أنه يمكن الانتهاء منها بسرعة أكبر وبشكل متسق. فكرة إنشاء مستخدمين بديلين لاختبار قابلية الاستخدام هي اتجاه وطموح وغاية لمجتمعات الذكاء الاصطناعي الحديثة.
اختبار A / B
في تطوير الويب وتسويقه، اختبار A / B أو كما يُعرف بـ"الاختبار المقسّم" يعد منهجاً تجريبياً وعملياً لتصاميم الويب (وخاصة تصميم تجربة المستخدم) ، والذي يهدف إلى تحديد التغييرات في صفحات الويب التي تزيد أو ترفع من نتائج الاهتمام (على سبيل المثال، معدل النقر أو ظهور لافتة إعلانية). كما يوحي الاسم، تتم مقارنة نسختين (A و B) ، وهما متطابقان باستثناء اختلاف واحد قد يؤثر على سلوك المستخدم. قد تكون النسخة A هي النسخة المستخدمة حالياً، بينما يتم تعديل الإصدار B من بعض النواحي. على سبيل المثال، في مواقع التجارة الإلكترونية، يعد مسار الشراء عادةً مرشحاً جيداً لاختبار A / B ، حيث أن التحسينات الهامشية في معدلات انخفاض الأسعار يمكن أن تمثل مكسباً كبيراً في المبيعات. يمكن رؤية تحسينات مهمة من خلال عناصر الاختبار مثل نسخ النص، والتخطيطات، والصور والألوان.
تشبه الاختبارات الخاصة بتعدد المتغيرات أو "اختبارات الجرافات" اختبار A / B ولكن تختبر هذه الاختبارات أكثر من نسختين في نفس الوقت.
عدد مواضيع الاختبار
في أوائل التسعينيات من القرن العشرين، قام جاكوب نيلسن ، وهو باحث في شركة صن مايكروسيستمز في ذلك الوقت، بتعميم مفهوم استخدام العديد من اختبارات قابلية الاستخدام الصغيرة - عادة مع خمسة مواضيع اختبار فقط - في مراحل مختلفة من عملية التطوير. حجته هي أنه بمجرد أن يتم العثور على شخصين أو ثلاثة أشخاص في حيرة من أمرهم في الصفحة الرئيسية، فلن يتم تحقيق الغرض من تصميم تلك الصفحة، حيث سيكون هنالك المزيد من الأشخاص الذين يعانون من نفس التصميم المعيب. تعد اختبارات قابلية الاستخدام التفصيلية مضيعة للموارد، وتأتي أفضل النتائج من خلال اختبار ما لا يزيد عن خمسة مستخدمين وتشغيل أكبر عدد ممكن من الاختبارات الصغيرة."
تم وصف معيار الـ"خمسة مستخدمين" لاحقاً من خلال نموذج رياضي[9] ينص على نسبة المشاكل الغير المكتشفة وذلك بترميز تلك المشاكل بالحرف U

حيث p هو احتمالية تحديد موضوع واحد لمشكلة محددة و n هو عدد المواضيع (أو جلسات الاختبار). يظهر هذا النموذج على أنه رسم بياني مقارب تجاه عدد المشاكل القائمة الحقيقية (انظر الشكل أدناه).
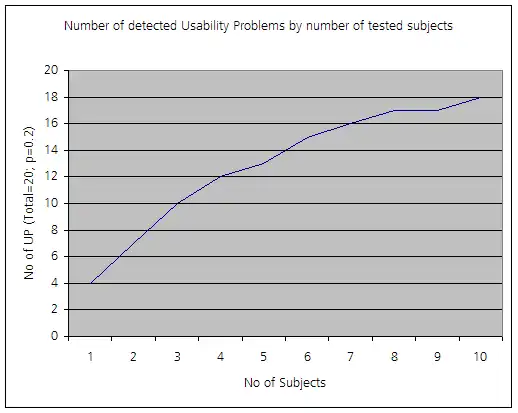
في بحث لاحق، تم استجواب مطالبة نيلسن بشغف مع كل من الأدلة التجريبية[10] ونماذج رياضية أكثر تقدماً.[11] التحديان الرئيسيان لهذا التأكيد هما:
- نظراً لأن قابلية الاستخدام مرتبطة بمجموعة محددة من المستخدمين، فمن غير المرجح أن يمثل حجم العينة الصغير هذا إجمالي السكان، وبالتالي فإن البيانات من هذه العينة الصغيرة من المرجح أن تعكس مجموعة أكثر من السكان الذين قد يمثلونها.
- ليست كل مشكلة في قابلية الاستخدام سهلة على حد سواء للكشف. تحدث مشاكل مستعصية لإبطاء العملية الكلية. في ظل هذه الظروف، يكون تقدم العملية أكثر ضحالة مما توقعته صيغة نيلسن / لاندوير.[12]
من المهم الإشارة إلى أن نيلسن لا يدعوا إلى التوقف عن اختبار قابلية الاستخدام بعد إجراء الاختبار على خمسة مستخدمين ؛ ولكن تتمثل وجهة نظره في أن الاختبار مع خمسة مستخدمين، وإصلاح المشكلات التي يكتشفونها، ثم اختبار الموقع الذي تمت مراجعته مع خمسة مستخدمين مختلفين هو أفضل استخدام للموارد المحدودة من إجراء اختبار قابلية استخدام مع 10 مستخدمين. في الممارسة العملية، يتم إجراء الاختبارات مرة واحدة أو مرتين أسبوعياً خلال دورة التطوير بأكملها، وذلك باستخدام ثلاثة إلى خمسة مواضيع اختبار لكل جولة، ويتم تسليم النتائج خلال 24 ساعة للمصممين. يمكن أن يصل عدد المستخدمين الذين تم اختبارهم بالفعل على مدار المشروع بسهولة إلى 50 إلى 100 شخص.
في مراحل مبكرة، عندما يُرجح أن يواجه المستخدمون على الفور مشاكل تمنعهم من السير في مساراتهم، يمكن استخدام أي شخص يتمتع بذكاء طبيعي تقريباً كموضوع اختبار. في المرحلة الثانية، سيقوم المختبرون بتوظيف مواضيع الاختبار عبر مجموعة واسعة من القدرات. على سبيل المثال، في إحدى الدراسات، لم يُظهر المستخدمون المتمرسون أي مشكلة في استخدام أي تصميم، من الأول إلى الأخير، بينما فشل المستخدمون الساذجون والمستخدمون ذوو القوة المحددة ذاتياً بشكل متكرر. [13] وفي وقت لاحق، بينما تتماشى مراحل التصميم، يجب تعيين وتخصيص المستخدمين من بين كل الأشخاص المستهدفين.
عندما يتم تطبيق هذه الطريقة على عدد كافٍ من الأشخاص على مدار المشروع، يتم التعامل مع الاعتراضات الموضحة أعلاه: حجم العينة ستتوقف على أن تكون صغيرة والمشاكل في قابلية الاستخدام التي تنشأ مع المستخدمين العرضيين فقط ستكون مكشوفة. تكمن قيمة الطريقة في حقيقة أن مشاكل التصميم المحددة، بمجرد مواجهتها وملاحظتها أو تدوينها، قد لا تُرى مرة أخرى لأنه يتم إزالتها فوراً، بينما يتم اختبار الأجزاء التي تبدو ناجحة مراراً وتكراراً. على الرغم من أنه قد يتم اختبار المشاكل الأولية في التصميم من قبل خمسة مستخدمين فقط، إلا أنه عند تطبيق الطريقة بشكل صحيح، فإن أجزاء التصميم التي نجحت في هذا الاختبار الأولي ستخضع للاختبار من 50 إلى 100 شخص.
مثال
الدليل الخاص بـ Apple Computer 1982 للمطورين ينصح باستخدام اختبار قابلية الاستخدام:[14]
- "حدد الجمهور المستهدف. ابدأ تصميم واجهة المستخدم البشرية عن طريق تحديد جمهورك المستهدف. هل تكتب وتصمم لرجال الأعمال أو للأطفال؟
- حدد مقدار معرفة المستخدمين المستهدفين حول أجهزة حواسب Apple وموضوع البرنامج.
- تسمح الخطوتين 1 و 2 بتصميم واجهة المستخدم لتناسب احتياجات الجمهور المستهدف. قد تفترض برامج إعداد الضرائب المكتوبة للمحاسبين أن مستخدميها لا يعرفون شيئاً عن أجهزة الحاسب ولكنهم خبراء في قانون الضرائب، بينما قد يفترض مثل هذا البرنامج المكتوب للمستهلكين أن مستخدميه لا يعرفون شيئاً عن الضرائب ولكنهم على دراية بأساسيات أجهزة حواسب Apple.
نصحت Apple المطورين بأنه "يجب أن تبدأ الاختبار في أقرب وقت ممكن، باستخدام الأصدقاء المقربين والأقارب والموظفين الجدد":[14]
"طريقة الاختبار لدينا هي على النحو التالي. أنشأنا غرفة مع خمسة إلى ستة أنظمة حاسب. نحن نقوم بجدولة مجموعتين إلى ثلاث مجموعات من خمسة إلى ستة مستخدمين في وقت واحد لتجربة الأنظمة (غالباً دون علمهم بأن البرنامج هو البرنامج الذي نريده وليس النظام الذي نختبره). لدينا اثنين من المصممين في الغرفة. لذلك، هم يتفقدون الكثير مما يجري حولهم. وأيضاً يستشعرون مدى حساسية المستخدمين كما لو أن هناك شخصا يعمل ويختبر معهم."
يجب على المصممين مشاهدة أشخاص يستخدمون البرنامج بشكل شخصي، حيث أن:[14]
وُجد بأن خمسة وتسعون بالمائة من الأخطاء والثغرات في التصميم يمكن تلافيها من خلال النظر في لغة الجسد الخاصة بالمستخدمين. وذلك يكمن من خلال نظرات المستخدمين وتحديقهم في الواجهات الرسومية وكيفية نقرهم على الكائنات التفاعلية. أيضاً, تم الملاحظة بأن لغة الجسد تلعب دوراً مهماً في التعرف ما إذا كان المستخدم راضٍ عن مستوى الخدمة من خلال تحريك رأسه أو هز كتفه. علاوة على ذلك، يمكن سؤال المستخدم عن كيفية تعامله مع أدوات النظام، وقد يكون من المدهش حقاً في بعض الأحيان عندما يتم الملاحظة بأن المستخدم قد لا يفصح عن العقبات التي مر بها وربما يتجاهلها.
التعليم
كان اختبار قابلية الاستخدام موضوعاً رسمياً للتعليم الأكاديمي في تخصصات مختلفة.[15]
المراجع
- Nielsen, J. (1994). Usability Engineering, Academic Press Inc, p 165
- Dennis G. Jerz (July 19, 2000). "Usability Testing: What Is It?". Jerz's Literacy Weblog. مؤرشف من الأصل في 25 أغسطس 2019. اطلع عليه بتاريخ 29 يونيو 2016. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Andreasen, Morten Sieker; Nielsen, Henrik Villemann; Schrøder, Simon Ormholt; Stage, Jan (2007). What happened to remote usability testing?. Proceedings of the SIGCHI Conference on Human Factors in Computing Systems - CHI '07. صفحة 1405. doi:10.1145/1240624.1240838. ISBN 9781595935939. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Dabney Gough; Holly Phillips (2003-06-09). "Remote Online Usability Testing: Why, How, and When to Use It". مؤرشف من الأصل في 15 ديسمبر 2005. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Dray, Susan; Siegel, David (March 2004). "Remote possibilities?: international usability testing at a distance". Interactions. 11 (2): 10–17. doi:10.1145/971258.971264. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Chalil Madathil, Kapil; Joel S. Greenstein (May 2011). Synchronous remote usability testing: a new approach facilitated by virtual worlds. Proceedings of the 2011 Annual Conference on Human Factors in Computing Systems. صفحات 2225–2234. doi:10.1145/1978942.1979267. ISBN 9781450302289. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Dray, Susan; Siegel, David (2004). "Remote possibilities?". Interactions. 11 (2): 10. doi:10.1145/971258.971264. الوسيط
|CitationClass=تم تجاهله (مساعدة) - "Heuristic Evaluation". Usability First. مؤرشف من الأصل في 4 مارس 2019. اطلع عليه بتاريخ April 9, 2013. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Virzi, R. A. (1992). "Refining the Test Phase of Usability Evaluation: How Many Subjects is Enough?". Human Factors. 34 (4): 457–468. doi:10.1177/001872089203400407. الوسيط
|CitationClass=تم تجاهله (مساعدة) - "Testing web sites: five users is nowhere near enough - Semantic Scholar". semanticscholar.org. 2001. مؤرشف من الأصل في 25 أغسطس 2019. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Caulton, D. A. (2001). "Relaxing the homogeneity assumption in usability testing". Behaviour & Information Technology. 20 (1): 1–7. doi:10.1080/01449290010020648. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Schmettow, Heterogeneity in the Usability Evaluation Process. In: M. England, D. & Beale, R. (ed.), Proceedings of the HCI 2008, British Computing Society, 2008, 1, 89-98
- Bruce Tognazzini. "Maximizing Windows". مؤرشف من الأصل في 23 ديسمبر 2017. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Meyers, Joe; Tognazzini, Bruce (1982). Apple IIe Design Guidelines (PDF). Apple Computer. صفحات 11–13, 15. مؤرشف من الأصل (PDF) في 24 مايو 2019. اطلع عليه بتاريخ أغسطس 2020. الوسيط
|CitationClass=تم تجاهله (مساعدة); تحقق من التاريخ في:|تاريخ الوصول=(مساعدة) - Breuch, Lee-Ann; Mark Zachry; Clay Spinuzzi (April 2001). "Usability Instruction in Technical Communication Programs". Journal of Business and Technical Communication. 15 (2): 223–240. doi:10.1177/105065190101500204. مؤرشف من الأصل في 10 ديسمبر 2019. اطلع عليه بتاريخ 03 مارس 2014. الوسيط
|CitationClass=تم تجاهله (مساعدة)
 بوابة علم الحاسوب
بوابة علم الحاسوب بوابة تقنية المعلومات
بوابة تقنية المعلومات
 صور وملفات صوتية من كومنز
صور وملفات صوتية من كومنز
