تصنيع كلامي
تصنيع الكلام أو اصطناع الكلام أو تخليق الكلام هو إنتاج اصطناعي للكلام البشري. ويسمى نظام الكمبيوتر المستخدم لهذا الغرض خطاب كمبيوتر أو توليف الكلام، ويمكن تنفيذها في منتجات البرامج أو الأجهزة. النص إلى كلام (TTS) نظام تحويل لغة النص العادي إلى الكلام؛ أنظمة أخرى تجعل رمزية التمثيل اللغوي مثل تحويل نسخ لفظي إلى كلام.[1]يمكن إنتاج الكلام المركب بواسطة وصل أجزاء من الحديث المسجل والذي يتم تخزينه في قاعدة بيانات. الأنظمة تختلف في حجم وحدات تخزين الكلام. نظام مخازن الهواتف أو diphone يوفر أكبر مجموعة إنتاج صوتي، ولكن قد تفتقر إلى الوضوح. لاستخدامات محددة المجال، ولتخزين الكلمات أو الجمل بأكملها بحيث يسمح لإنتاج عالي الجودة. بدلا من ذلك يمكن للمازج الصوتي أن يدمج نموذج الجهاز الصوتي ذو خصائص أخرى للصوت البشري لإنشاء إخراج صوتي "اصطناعي" تماما.[2] TTS أو Text-to-Speech هي تقنية تكنولوجية لمحاكاة الصوت البشري باستعمال الحاسوب أو أنظمة نطق مختلفة. المهمة الرئيسية لمحرك TTS هي تحويل الكلمات المكتوبة أو المخزنة على شكل نصوص إلى كلمات منطوقة بصوت بشري. من أشهر الشركات التي تطور تقنية للغة العربية هي شركة صخر للحاسب الآلي.

جودة تخليق الكلام يتم تقييمها قياساً على التشابه مع صوت الإنسان وقدرته على أن يكون مفهوماً بشكل واضح. يسمح البرنامج الذكي تحويل النص إلى كلام للناس الذين يعانون من ضعف البصر أو إعاقة قراءة للاستماع إلى الأعمال المكتوبة على كمبيوتر المنزل. وشملت العديد من أنظمة تشغيل الكمبيوتر لتخليق الكلام منذ أوائل التسعينات.
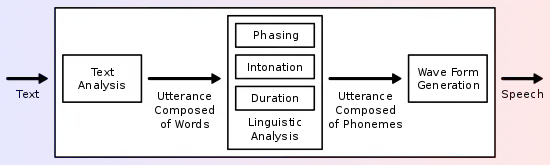
ويتألف نظام تحويل النص إلى كلام (أو "المحرك") من جزئين :[3] و معالج الواجهة الأمامية الأمامي و معالج الواجهة الخلفي. الواجهة الأمامية واثنتين من المهام الرئيسية. أولا: أنه يحول النص الخام الذي يحتوي على رموز مثل الأرقام والمختصرات إلى مايعادل كلمات مكتوبة بها. وغالبا ما تسمى هذه العملية تطبيع النص، ما قبل المعالجة، أو ترميز' ' الواجهة الأمامية ثم يعين نسخ لفظي في علوم الكمبيوتر، التحليل المعجمي هو عملية تحويل سلسلة من الأحرف (كما هو الحال في برنامج كمبيوتر أو صفحة ويب) إلى سلسلة من الرموز (سلاسل مع "معنى" محدد) بالنسبة لكل كلمة، والأجزاء، وتحديد النص في وحدة لحنية، مثل شبه جملة شرط ، والجملة. ويطلق على عملية تعيين التدوين الصوتي لعبارة أي تحويل النص إلى صوت أو حرف من حروف اللغة -إلى صوت تحويل. التدوين الصوتي ومعلومات علم العروض التي يشكلون معا التمثيل اللغوي الرمزي الذي يتم إخراجه من قبل الواجهة الأمامية. والواجهة الخلفية، غالبا ما يشار إليها باسم المزج أو التوليف - ثم تقوم بتحويل التمثيل اللغوي الرمزي إلى صوت. في بعض الأنظمة، فإن هذا الجزء يشمل حسابات تستهدف علم العروض "" (درجة الصوت فترات الصوت),[4] وهو بعد ذلك يحدد الخطاب المفترض على الإنتاج الصوتي.
التاريخ
قبل فترة طويلة من اختراع معالجة الإشارات الإلكترونية ، كان هناك أولئك الذين حاولوا بناء آلات لخلق كلام الإنسان. بعض الأساطير الأولى التي تسرد وجود الرأس الوقحة [الإنجليزية] تتضمن ذكر البابا سيلفستر الثاني (1003 م)، ماغنوس (1198-1280)، وروجر بيكون (1214-1294).
في 1779، والعالم الدانماركي كريستيان كراتزنشتاين، الذي بعمل في أكاديمية العلوم الروسية، الذي بنى نماذج حول أداة إخراج الصوت البشرى التي يمكن أن تنتج خمسة أصوات أحرف علة طويلة ( ويكيبيديا:الألفبائية الصوتية الدولية التدوين، فهي[a:], [e:], [i:], [o:] and [u:]).[5] وأعقب هذا تشغيل "آلة التحدث لفولفجانغ فون كمبلين من قبل كير -" من قبل فولفغانغ فون كمبلين من برسبورغ، المجر، هو موضح في ورقة 1791.[6] هذا الجهاز أضاف نماذج من اللسان والشفتين، مما مكنها من إنتاج أحرف صامتة وكذلك أحرف العلة. في 1837، تشارلز يتستون أنتج "الآلة الناطقة" على أساس تصميم فون كمبلين، وفي 1857، بني M. فابر في "يوفون". وقد بعث تصميم يتستون في 1923 من قبل باجيت.[7]
اقرأ أيضًا
مراجع
- Allen, Jonathan; Hunnicutt, M. Sharon; Klatt, Dennis (1987). From Text to Speech: The MITalk system. Cambridge University Press. ISBN 0-521-30641-8. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Rubin, P.; Baer, T.; Mermelstein, P. (1981). "An articulatory synthesizer for perceptual research". Journal of the Acoustical Society of America. 70 (2): 321–328. doi:10.1121/1.386780. الوسيط
|CitationClass=تم تجاهله (مساعدة) - van Santen, Jan P. H.; Sproat, Richard W.; Olive, Joseph P.; Hirschberg, Julia (1997). Progress in Speech Synthesis. Springer. ISBN 0-387-94701-9. الوسيط
|CitationClass=تم تجاهله (مساعدة) - Van Santen, J. (April 1994). "Assignment of segmental duration in text-to-speech synthesis". Computer Speech & Language. 8 (2): 95–128. doi:10.1006/csla.1994.1005. الوسيط
|CitationClass=تم تجاهله (مساعدة) - History and Development of Speech Synthesis, Helsinki University of Technology, Retrieved on November 4, 2006 نسخة محفوظة 27 أبريل 2014 على موقع واي باك مشين.
- Mechanismus der menschlichen Sprache nebst der Beschreibung seiner sprechenden Maschine ("Mechanism of the human speech with description of its speaking machine," J. B. Degen, Wien). (بالألمانية)
- Mattingly, Ignatius G. (1974). Sebeok, Thomas A. (المحرر). "Speech synthesis for phonetic and phonological models" (PDF). Current Trends in Linguistics. Mouton, The Hague. 12: 2451–2487. مؤرشف من الأصل (PDF) في 4 مارس 2016. الوسيط
|CitationClass=تم تجاهله (مساعدة)
 بوابة علم الحاسوب
بوابة علم الحاسوب بوابة تقنية المعلومات
بوابة تقنية المعلومات